נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מדריך זה נלקח מויקיספר
שפת C היא אחת משפות התכנות הנפוצות ביותר. השפה נמצאת רק רמה אחת מעל שפות הסף הבסיסיות, וידועה בפשטותה, קצרנותה, חסכנותה במשאבים, ויעילותה הגבוהה. פשטותה היחסית של השפה הופכת אותה לבחירה נפוצה כשפת התכנות הראשונה אותה לומדים. יש גם הרואים בה דרישת קדם ללימוד ++C, שהיא (במידה מסויימת) הרחבה שלה.
לשפה שימושים רבים, בעיקר בתחומים בעלי דגש על ביצועים גבוהים: מערכות הפעלה, מסדי נתונים, ומשחקים. קוד הליבה של מערכות ההפעלה לינוקס, חלונות ומקינטוש כתוב בשפת C.
איזה ידע קודם נדרש?[]
- נסיון בסיסי בעבודה עם מחשבים נדרש, שכן להפעלת תוכנות בשפה יש להשתמש במחשב.
- הכרת אנגלית יכולה לסייע מאוד, שכן השפה משתמשת באנגלית, ורוב התיעוד של השפה הוא בשפה האנגלית.
אין צורך בהכרה מוקדמת של השפה או של שפות תכנות אחרות - הספר מלמד את עקרונותיה החל מהבסיס.
קישורים חיצוניים[]

|
שפות תכנות |
|---|
|
ActionScript - Ada - ALGOL - ASP - ASP.NET - Assembly x86 - bash - BASIC - Brainfuck - C - C++ - C# - Cobol - CSS - Delphi - Fortran - Game Maker - Haskell - HPL - HTML - Java - JavaScript - Lingo - LISP - Logo - MIPS - Ook! - Pascal - Perl - PHP - PL/I - PL/SQL - PowerBuilder - Prolog - Python - REXX - Ruby - Shakespeare - Smalltalk - SQL - TCL - VB - VB .NET\2005 - XML מאמא |
הכנה
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
הרכיבים הנדרשים לפיתוח ב-C[]
כדי לפתח בשפת C, יש להשתמש במספר רכיבים שיפורטו להלן.
עורך טקסטים[]
ראשית, יש להשתמש בעורך טקסטים כדי לכתוב את הקוד. חשוב להשתמש בתכנה המאפשרת לשמור קבצי טקסט פשוטים (ללא סימני עריכה כלשהם). להלן מספר עורכי טקסט המתאימים לפיתוח. חלקם תומך בתכונות כמו highlighting, יישור אוטומטי, סימון פיסקאות, השלמה אוטומטית של מילים, ועוד. ראוי לציין כי עורכי הטקסט שמוצגים כאן אינם מוגבלים לתמיכה בשפה זו או אחרת, אלא מתאימים למגוון רחב של שפות תכנות שונות.
לינוקס[]
- מספר עורכים מגיעים כחלק אינטגרלי משולחנות העבודה השונים:
- GEdit- עורך טקסטים המותקן עם Gnome. ניתן להתאמה בעזרת מערכת גמישה של רכיבי plugin.
- Kate - עורך MDI המגיע עם KDE.
- KWrite - עורך SDI, המגיע עם KDE.
- Mousepad - עורך טקסט מינימלי המגיע עם שולחן העבודה Xfce.
- מספר עורכי טקסט נפוצים מאד, אך מתאפיינים בממשק מסובך או טקסטואלי, היכול להקשות על מי שלא התרגל אליהם:
- Emacs- עורך טקסט משוכלל, המציג רשימה ארוכה מאוד של תכונות, ותמיכה במגוון של אפשרויות עבודה. הוא דורש זמן לימוד מסויים, מכיוון שהממשק שלו מעט שונה משל מרבית הממשקים המוכרים.
- vi, Vim
- nano - עורך זעיר בעל מימשק טקסטואלי לחלוטין.
ניתן להתקין את כל העורכים הנ"ל בעזרת מנהלי החבילות המתאימים.
חלונות[]
- Notepad - עורך הטקסט הבסיסי שמגיע עם חלונות. הוא בסיסי לחלוטין ואינו מכיל אף תכונה שימושית לתכנות, לכן מומלץ שלא לעבוד איתו אלא בהיעדר אלטרנטיבה.
- Notepad++ - עורך טקסט חופשי המותאם לפיתוח, בעל הרבה תכונות שימושיות.
- Emacs - את גירסת החלונות של Emacs ניתן להשיג כאן (קבצי ההתקנה המוכנים הם= אלו שמופיעה בשמם המילה bin. כדי להשיג את הגירסה העדכנית ביותר, הורידו את הקובץ emacs-22.1-bin-i386.zip).
- SciTE
- Open Komodo
מקינטוש[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
המהדר והמקשר[]
לאחר שהקוד כתוב, המהדר (compiler בלעז) ממיר את הקוד הכתוב לשפת מכונה, והמקשר (linker בלעז) מקשר במידת הצורך מספר קבצי שפת מכונה. שפת C, כרוב שפות התכנות, מוגדרת בעזרת כללים נוקשים למדי. במידה שהקוד מכיל "שגיאות דקדוק" (כלומר, שהקוד אינו כתוב לפי כללי השפה), המהדר (ולעתים המקשר) יודיעו על שגיאות.
gcc הוא קומפיילר חופשי כמעט לכל סוגי הפלטפורמות. במערכת לינוקס תוכל להתקין אותו (אם אינו כבר מותקן) בעזרת מנהל ההתקנות של המערכת שלך, ובמערכת חלונות תוכל להוריד את חבילת MinGW הכוללת מהדר וכלים בסיסיים נוספים כאן.
הספריה הסטנדרטית[]
שפת C תוכננה כך שתהיה קטנה מאד, ובניגוד לשפות אחרות, איננה כוללת אפילו פקודות לפעולות בסיסיות כקלט ופלט. במקום זאת כוללת השפה הגדרה מפורטת לספריה סטנדרטית, והמהדר (ובעיקר המקשר) מטמיעים את יכולת ספריה זו בקבצי ההרצה. ספריה זו מותקנת יחד עם המהדר והמקשר, ולכן אין צורך (בדרך כלל) בהתקנתה בנפרד.
כלים אחרים[]
לעתים משתמשים בכלים נוספים כדי להקל על הפיתוח בשפת C. הנפוץ ביותר, מנפה שגיאות (debugger בלעז), הוא יישום המאפשר לעקוב אחרי פעולות התכנית בזמן ההרצה. בלינוקס תוכל להשתמש בgdb (ראו גם מילון פקודות ב-GDB). ישנם עוד כלים רבים בנוסף (לדוגמה profiler, האוסף נתונים על תזמון תכנית בזמן הרצתה), אך כלים אלה (כולל מנפה השגיאות) אינם הכרחיים לצורך הפיתוח.
סביבות פיתוח[]
יש המעדיפים לעבוד בשילוב של הרכיבים שבהם כבר דנו: למצוא עורך טקסטים המתאים להם, מהדר כזה או אחר, וכולי. מאידך, ישנן תוכנות הנקראות סביבות פיתוח, המאגדות כבר את הרכיבים הנדרשים לפיתוח, ויש המעדיפים להשתמש בהן.
תוכנות חופשיות[]
- lcc-win32 - סביבת פיתוח חופשית (לשימוש לא מסחרי), לחלונות.
- Dev C++ - סביבת פיתוח חופשית נוספת, לחלונות.
- Code::Blocks - סביבת פיתוח חופשית למגוון מערכות הפעלה.
- Anjuta - סביבת עבודה קלה, עבור לינוקס.
- Pelles C IDE - סביבת פיתוח חופשית. ניתן להוריד מכאן, מיועדת לחלונות.
- eclipse היא סביבת עבודה המיועדת ל-Java, ופועלת על כל מערכת הפעלה. התוסף eclipse-cdt מוסיף אפשרויות עבודה עם C/C++. מדריך (באנגלית) להתקנת התוסף ניתן למצוא כאן (קובץ PDF).
תוכנות מסחריות[]
- Microsoft Visual Studio - סביבת פיתוח נפוצה של חברת מיקרוסופט. ניתן להוריד גירסת לימוד חינמית (דורשת רישום קצר) מאתר חברת מייקרוסופט. גירסת ה-C++ היא הגירסה הדרושה. היא, מן הסתם, מיועדת לחלונות בלבד.
- סביבת הפיתוח של חברת Borland - סביבת פיתוח של חברת בורלנד.
- סביבת העבודה NetBeans (מיועדת לעריכת java ו- jee) מציעה תוסף עבור C/C++ כאן.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
שלום עולם!
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
נהוג לפתוח תיאור של שפת תכנות באמצעות הצגת תכנית פשוטה המדפיסה "שלום עולם!" למסך. בכך ניתן לראות את המבנה הבסיסי של שפת התכנות ואת הדרך שבה היא מבצעת הדפסות למסך. לא נחרוג ממנהג זה כאן.
התוכנית הראשונה[]
פתח את עורך הטקסטים המועדף עליך (או סביבת הפיתוח שלך), וכתוב שם:
#include <stdio.h>
int main()
{
printf("Hello world\n");
return 0;
}
מקוד זה ניתן לייצר תוכנית המדפיסה על המסך את המילים Hello world.
הסבר על הקוד[]
שורה 1[]
#include <stdio.h>
מוסיפים שורה זו לתוכניות שמבצעות פלט וקלט, כלומר, מתקשרות עם המשתמש דרך המסך והמקלדת.
בהמשך נראה שהשורה היא הוראה לקדם מעבד להכליל את הקוד בקובץ הנמצא בסוגריים (stdio.h במקרה הנ"ל) לשימוש בקוד הנכתב.
שורה 2[]
int main()
שורה זו מסמנת את המקום בו הקוד מתחיל לרוץ. בכל תכנית C בה כתובה שורה זו, הקוד מבצע את הפקודות שבין הסוגריים המסולסלים המופיעים מיד לאחר שורה זו.
בהמשך נראה ששורה זו פותחת את הפוקנציה הראשית ממנה הקוד מתחיל לרוץ. בכל תוכנית C חייבת להיות פונקציה אחת ויחידה כזו. את הקידומת int נבין בהמשך. הסוגריים הריקים אומרים ששום ערך אינו מועבר לפונקציה.
שורה 3[]
{
שורה זו מסמנת את תחילת רצף הפקודות שאותו מתחילה התוכנית לבצע.
בהמשך נראה ששורה זו פותחת בלוק, כלומר אוסף הוראות או פקודות המהוות יחידת קוד אחת. במקרה זה הבלוק הוא של ההוראות השייכות לפונקציה main.
שורה 4[]
printf("Hello world\n");
שורה זו מדפיסה למסך את המילים "Hello world".
בהמשך נראה הסבר מפורט לשורה זו בפלט וקלט.
שורה 5[]
return 0;
שורה זו מודיעה למערכת ההפעלה שהכל התנהל כשורה.
בהמשך נראה ששורה זו קובעת את הערך המוחזר של הפונקציה main.
שורה 6[]
}
שורה זו מסמנת את סיום רצף הפקודות שאותו מבצעת התכנית.
בהמשך נראה ששורה זו סוגרת בלוק - במקרה זה, הבלוק של ההוראות השייכות לפונקציה main.
בניית והרצת התכנית[]
לאחר שכתבת את הקוד, בנה את הקוד לתכנית, והרץ את התוכנית. בניית הקוד והרצת התכנית משתנים בהתאם למערכת ההפעלה.
gcc בלינוקס או Cygwin[]
שמור את קוד התכנית בתיקיה שבה יש לך ההרשאות המתאימות. נהוג להשתמש בסיומת c לקבצי קוד כגון זה שכאן. נניח ששמרת את הקוד בקובץ שנקרא hello_world.c. כעת עלינו לבנות את הקוד ולהפכו לתכנית. פתח טרמינל, וכתוב:
אם ההידור יעבור בהצלחה, יווצר קובץ בשם hello.out. ניתן להריץ את התכנית ע"י כתיבה בטרמינל:
ותראה את המילים Hello world מודפסות.
|
|
כדאי לדעת: הסיבה לקידומת ה /. היא שבהפצות לינוקס רבות ברירת המחדל לא מאפשרת הרצה של קבצים באופן ישיר מתיקיית הבית של המשתמש. לעיתים זה מאופשר (תלוי בהפצה ובהגדרות המשתמש) ואז הקידומת הזו מיותרת. |
באופן כללי בונים קוד בצורה:
כאשר source_file הוא שם קובץ הקוד, וexecutable הוא שם קובץ התוכנית המתקבלת (ראה שימוש בסוגריים משולשים בסימונים בספר). מריצים בצורה:
כאשר executable הוא שם קובץ התוכנית.
|
|
עכשיו תורך: נניח ששמרת את הקוד בקובץ my_first_program.c, ואתה רוצה לבנות ממנו את הקובץ it_runs.out. כיצד תבנה, ומה תריץ? |
פתרון
כדי לבנות, יש לכתוב:
כדי להריץ, יש לכתוב:
סביבת פיתוח בחלונות[]
|
|
כדאי לדעת: ברוב סביבות הפיתוח בחלונות, הרצת תוכנית כזו תפתח חלון אשר ייסגר מיד לאחר סיום התכנית, דבר שעלול להקשות על קריאת הפלט. אם הדבר אכן קורה, הוסף שתי שורות לקוד, שיראה עתה כך:#include <stdio.h>
#include <conio.h>
int main()
{
printf("Hello world\n");
getch();
return 0;
}
|
Microsoft Visual Studio[]
אם אתם משתמש ב-Microsoft Visual Studio, תוכלו לפעול לפי הצעדים הבאים. על אף שקיימים הבדלים בין גרסות שונות, הם אינם משמעותיים. בגרסה 2005 ניתן לעשות זאת כך:
- פרוייקט חדש – כנסו לתפריט File → New → Project.... מצאו תחת קטגוריה "Visual C++" את סוג הפרוייקט "Win32 Console Application" ובחרו אותו. הזינו שם לפרוייקט ואת המסלול בו תיווצר התיקיה של הפרוייקט. ניתן להוריד את הסימון "Create Directory for Solution", על מנת שתיווצר תיקייה אחת פחות. לחצו על OK. באשף שיפתח, עברו ל-Application Settings או לחצו על Next. בחלון זה סמנו את "Empty project" וסיימו עם לחיצת Finish. כעת נוצרה לכם תיקייה במסלול שהזנתם עם שם הפרוייקט ובה קבצים של הפרוייקט; כרגע הוא ריק.
- יצירת קובץ C חדש – כדי ליצור קובץ C חדש, כנסו לתפריט Project → Add New Item.... מהחלון שנפתח בחרו את סוג הקובץ "C++ File" והזינו את שם הקובץ (לדוגמה main.c), זכרו להוסיף את הסיומת ".c" כדי שהקובץ יהודר כתוכנית C ולא כתוכנית C++.
- הוספת קובץ C קיים – כדי להוסיף קובץ C קיים, רצוי תחילה להעתיקו לתיקיית הפרויקט. לאחר מכן יש לבחור מהתפריט Project → Add Existing Item.... בחלון שיופיע, יש לבחור את הקבצים שברצונכם להוסיף.
- עריכת קוד – על מנת לערוך את אחד מקבצי הפרוייקט, יש ללחוץ עליו פעמיים בחלון "Solution Explorer".
- הידור והרצה – כדי לבנות את הפרוייקט (להדר ולקשר), יש לבחור לבחור את Build → Build Solution. אם ההידור יעבור בהצלחה יווצר קובץ הרצה בתיקיית Debug בתוך תיקיית הפרוייקט. כדי להריץ תחת מנפה שגיאות יש לבחור את Debug → Start Debugging. אם יהיו שגיאות בזמן ההידור, הן תופענה בחלון Output או Task List. לחיצה כפולה על שגיאה תביא אותכם לשורה בה הייתה השגיאה.
לא צוינו כאן קיצורי המקשים, מכיוון שהם יכולים להשתנות. כמו כן תוכלו לשנות את ההגדרות (אם הן עדיין לא כאלה) כך שהפרוייקט יהודר אוטומטית בכל פעם כשאתם מריצים (לרוב על ידי מקש F5). במקרה זה, כדאי להגדיר כך שלא תורץ הגרסה האחרונה שהודרה במקרה שהיו שגיאות הידור בגרסה חדשה.
כברירת מחדל מהודרת גרסת Debug של הפרוייקט. בגרסה זו, המהדר אינו עושה אופטימיזציה; בנוסף, הוא משאיר מידע נוסף בקובץ ההרצה החיוני למנפה שגיאות, דבר המגדיל מעט את קובץ ההרצה. כאשר תרצו להדר גרסה סופית של הפרוייקט (כדי להפיצו למשל), תוכלו לבחור ב-Release במקום Debug (בתוך תיבה על סרגל הכלים הראשי).
כאשר תרצו להקטין את נפח הפרוייקט (למשל כשתגבוהו או תשלחוהו במייל), תוכלו לנקותו מתפריט Build → Clean Solution או למחוק ידנית את תיקיות ה-Debug וה-Release ואת הקבצים עם הסיומות: ncb, suo, user, aps.
השתמש בסביבת הפיתוח שלך כדי להדר את הקוד. אם ההידור יעבור בהצלחה, יווצר קובץ מתאים בעל סיומת exe, ויהיה ניתן להריצו.
סביבות פיתוח אחרות[]
השתמש בסביבת הפיתוח שלך כדי להדר את הקוד. אם ההידור יעבור בהצלחה, יווצר קובץ מתאים בעל סיומת exe, ויהיה ניתן להריצו.
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
תרגילים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
שלום עולם! מותאם אישית[]
הפוך/י את הדוגמה הבסיסית לאישית יותר, על ידי הוספת שימך להדפסה. אם שמך ענת, לדוגמה, שנה/י את הקוד כך שידפיס Hello World, Anat. בדוק/בדקי שהנך מצליח לערוך את השינויים, להדר את הקוד, ולהריץ את התכנה החדשה.
הפתרון
#include <stdio.h>
int main()
{
printf("Hello World, Anat\n");
return 0;
}
הערות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
הערות בשפה אנושית (לרוב אנגלית) בקוד יכולות לשפר את בהירותו.
הערות קלאסיות (מרובות שורה)[]
בשפת C אפשר לכתוב הערות כלשהן בין רצפי-התווים /* לבין */. לדוגמה:
/* This is a comment. */
המהדר מתעלם מכל מה שנמצא בין רצפי התווים הנ"ל.
הערות בסגנון זה יכולות להכיל יותר משורה יחידה:
/* This is a comment, but
it is not limited to a single line. It spans
multiple lines. */
הערות בסגנון החדש[]
באיזור שנת 2000 אימצה שפת C, בתקן C99, גם הערות "סגנון חדש", מהסוג הנהוג גם בC++. הערות אלה, המוגבלות כל אחת לשורה יחידה, מתחילות בתווים //, ונמשכות עד סוף השורה:
// This is a new-style single line comment.
|
|
שימו לב: לא כל המהדרים תומכים בהערות בסגנון החדש. ככל שמהדר ישן יותר, כך גדל הסיכון שהוא אינו תומך בכך. |

השימוש בהערות[]
משתמשים בהערות כדי להבהיר את משמעותם של קטעי קוד שונים, או איך להשתמש בהם. בספר זה לעתים נשתמש בקטעי קוד כדי להסביר בתוך הקוד נקודות חדשות לגבי השפה. לדוגמה, בתוכנית שלום עולם! היינו יכולים להוסיף הערה בקוד, המסבירה היכן התוכנית מתחילה לרוץ:
#include <stdio.h>
/* The program starts running here. */
int main()
{
printf("Hello World\n");
return 0;
}
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
תרגילים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
שלום עולם! מותאם אישית[]
הוסף הערה בתוכנית שלום עולם! המציינת את השורה המדפיסה למסך.
הפתרון
#include <stdio.h>
int main()
{
/* This line prints to the screen "Hello world". */
printf("Hello world\n");
return 0;
}
משתנים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
על מנת שתכנית תוכל לשמור מידע (לדוגמה מקלט), לעבד מידע בחישובים מתמטיים, או לקבל החלטות על סמך מידע, יש לשמור את המידע במשתנים. משתנים הם כמעין "תיבות" שבהן שומרים דברים. לכל משתנה יש שם ותוכן. שם המשתנה מאפשר לנו לגשת למידע. תוכן המשתנה הוא הערך שאותו אנו מחפשים.
מהם משתנים?[]
לעתים קרובות אפשר לראות בקוד C קטעי קוד מהצורה:
int grade = 80;
קטע זה מצהיר על משתנה ששמו grade, וטיפוסו שלם (int); המשתנה מאותחל לערך 80. כעת, במקום להשתמש במספר 80, נוכל להשתמש במשתנה grade.
אפשר לחשוב על משמעות הקטע הקצר הזה בהשאלה מתיבות. אנו מודיעים למהדר על קיום "תיבה" שמתאימה למספרים שלמים: בכל עת, התיבה יכולה להכיל מספר שלם יחיד. שם התיבה הזאת הוא grade. הערך הראשון שאנו מכניסים לתיבה זאת הוא 80.
טיפוסים[]
שפת C היא שפה נמוכה יחסית, כלומר שפה שבה בולט מאד מבנה המחשב עליו היא רצה.
|
|
הגדרה: בתים המחשב מארגן מידע בבתים שהם יחידות הזיכרון הבסיסיות של המחשב. בכל מחשב יכול בית להכיל אחת מ256 אפשרויות, אך יש מחשבים בעלי בתים גדולים יותר, היכולים להכיל טווח אפשרויות גדול יותר. |
בשאר הפסקה נניח כדוגמה בית של 256 אפשרויות. אם נבנה "תיבה" מבית אחד, אז נוכל לשים שם אחת מ256 אפשרויות. אם נבנה "תיבה" משני בתים, אז נוכל לשים שם אחת מ256 * 256 אפשרויות. ככל שתיבה נבנית מיותר בתים, היא צורכת יותר מקום אך יכולה להכיל יותר אפשרויות. שפת C נבנתה ליעילות וחסכנות רבה. לכן, כשמגדירים בה משהו, ובפרט משתנים, יש להגדיר בדיוק את טיפוס המשתנה, הקובע דברים אלה.
הטיפוסים הבסיסיים ב- C נחלקים לשני סוגים: טיפוסים שלמים, וטיפוסי נקודה צפה. נעסוק כעת בכל אחד משני סוגים אלה.
טיפוסים שלמים[]
טיפוסים אלו נועדו לאכסן מספרים שלמים.
סווג עיקרי[]
יש שני סוגי שלמים עיקריים:
- char - טיפוס הנועד לשמירת תווים או מספרים חיוביים קטנים
- short int, int, long int - טיפוסים שנועדו לאכסן מספרים שלמים גדולים יותר, בהתאמה
בתרשים הבא, לדוגמה, אפשר לראות שני משתנים. האחד, grade, בנוי משני בתים, ומכיל את המספר 80. השני, c, מורכב מבית אחד, ומכיל את התו 'a':

השפה קובעת שגודלו של char הוא בית אחד בדיוק. לגבי שאר הטיפוסים, השפה אינה מגדירה במדויק את גדלי וטווחי המשתנים. ברוב המחשבים, לדוגמה, משתנה שלם תופס 4 בתים, אך קיימים מעבדים שבהם משתנה שלם תופס 8 בתים. תקן השפה קובע לרוב רק טווחים מינימליים. לדוגמה, התקן קובע שמשתנה שלם צריך לתפוס לפחות 2 בתים. תוכל לראות את תקן השפה לגבי טווחי טיפוסים שלמים בנספח טווחי טיפוסים שלמים.
שפת C ידועה בקצרנותה. אפשר לכתוב long כקיצור לlong int, ואפשר לכתוב short כקיצור לshort int.
ציון סימן[]
טיפוסים שלמים יכולים להכיל הן מספרים חיוביים והן מספרים שליליים. הטווח הוא סימטרי. כך, לדוגמה, במחשב שבו שלם (int) יכול להכיל 65,536 אפשרויות, הוא יוכל להכיל את כל המספרים השלמים החל מ-32,767 ועד ל32,767. לעתים יודעים מראש שמשתנה יוכל לקבל מספרים לא-שליליים בלבד. כך, לדוגמה, אם משתנה אמור להכיל משכורת בשקלים, אין טעם לחשוב על אפשרויות שליליות. השפה מאפשרת לקבוע האם טיפוס שלם יכול לקבל ערכים שליליים או לא. אם נציין שטיפוס לא יכול לקבל מספרים שליליים, נוכל לשמור בו מספרים יותר גדולים. כך, לדוגמה, נוכל לשמור במשתנה מספרים עד 65,535.
כשמגדירים טיפוס שלם, ניתן להוסיף את הקידומת signed או unsigned, המציינת האם המשתנה יכול לקבל ערכים שליליים או לא. לדוגמה:
signed int temperature;
מצהיר על משתנה שלם temperature שיכול לקבל גם ערכים שליליים (שלמים כמובן). מצד שני, לדוגמה:
unsigned int salary;
מצהיר על משתנה שלם salary שיכול לקבל ערכים לא-שליליים בלבד (שלמים כמובן).
אפשר גם להצהיר על משתנים בלי לציין את סימנם, לדוגמה כך:
int temperature;
int salary;
אך אז צריך להזהר. התקן מציין שint הוא signed כברירת מחדל, ואינו מציין דבר לגבי char. אם לא מציינים במפורש את סימנו של char, עלולה להתקבל התנהגות שמשתנה ממערכת למערכת.
טיפוסי נקודה צפה[]
טיפוסים אלה נועדו לאכסן מספרים רציונאליים. הטיפוסים נקראים מספרי נקודה צפה על שם השיטה רבת-הדיוק בה משתמש המחשב כדי לאחסן אותם.
- float- טיפוס רציונאלי בעל יכולת דיוק בינונית
- double וlong double- טיפוסים בעלי יכולת דיוק גבוהה וגבוהה במיוחד.
גם כאן אין השפה קובעת את גדליהם של הטיפוסים, והם יכולים להשתנות ממחשב למחשב. השפה רק מחייבת שגדלו של double יהיה לפחות גדלו של float, וגדלו של long double יהיה לפחות גדלו של double. גם כאן, ככל שמשתנה גדול יותר, דיוקו עולה.
קבועים[]
כל מספר שמופיע בקוד שפת C הוא בעל טיפוס כלשהו. לדוגמה, אם מופיע בקוד 80, אז זהו קבוע מטיפוס שלם (int).
הצהרה על משתנים[]
כדי להשתמש במשתנים בשפת C, יש להצהיר מהו טיפוס המשתנה ושמו. כאן נראה מהי צורת ההצהרה, ומהם השמות שאפשר לתת למשתנים.
צורת ההצהרה[]
בהצהרה על משתנה יש לרשום את טיפוס המשתנה, לאחריו רווח, לאחריו שם המשתנה, ולאחריו התו ;
<type> <name>;
(ראה שימוש בסוגריים משולשים בסימונים בספר.) לדוגמה, כדי להצהיר על משתנה בשם x המקבל ערכים שלמים (int), יש לרשום
int x;
אם יש מספר משתנים מאותו סוג, אפשר לרשום את סוג המשתנה, רווח, ואחריו את כל המשתנים מאותו הסוג ובניהם פסיקים. למשל:
int x, y;
float grade1, grade2, grade_average;
שמות משתנים[]
מומלץ לתת למשתנים שמות המתארים את מטרותיהם. כך, לדוגמה, אם יש צורך במשתנה המכיל ממוצע ציונים, עדיף לקרוא לו grade_average, ולא x. הדבר מקל על קריאת ותחזוקת הקוד. כמובן שהמהדר אינו יכול לאכוף כלל זה. למהדר ישנן מגבלות מעטות לגבי שמות משתנים:
- אין להשתמש במילים שמורות עבור שם של משתנה. כך, לדוגמה, אי אפשר לתת למשתנה את השם int. תוכל לראות את רשימת המילים השמורות בנספח מילים שמורות.
- שם המשתנה יכול להכיל רק אותיות אנגליות (גדולות וקטנות), מספרים, וקו תחתון. שם המשתנה חייב להתחיל באות או קו תחתון. כך, לדוגמה, option2 הוא שם חוקי למשתנה, אך 2option איננו.
- לכל משתנה חייב להיות שם ייחודי (נרחיב על כך בטווח ההכרה של משתנים). השפה מבדילה בין אותיות אנגליות גדולות לקטנות, ולכן השם Foo נבדל מfoo.
השורות הבאות הן טעות:
/* char is not a valid name for a variable! */
int char;
int x;
/* This variable was already declared. */
int x;
/* A variable name cannot start with 3. */
int 3db;
עבודה עם משתנים[]
לאחר הצהרה על משתנים, אפשר לעשות אתם דברים רבים. נתאר כאן בקצרה חלק מהם.
השמה[]
כדי להכניס ערך למשתנה כותבים את שם המשתנה, אחריו סימן שווה, ואחריו את התוכן שרוצים להכניס:
int a, b;
a = 3;
b = 7 + 8;
הדבר ידוע בשם השמה.
אתחול[]
אפשר גם להכניס ערך למשתנה מיד כשמצהירים עליו:
int a = 3, b = 7 + 8;
הדבר ידוע בשם אתחול.
פעולות חשבוניות[]
אפשר לבצע מגוון של פעולות חשבוניות על משתנים. להלן דוגמה קצרה:
int main()
{
int a = 7, b = 3, c;
c = a + b; /* now c is 10 */
a = 5; /* c is still 10 */
c = a - 1; /* now c is 4 */
return 0;
}
נעסוק בכך בפעולות חשבוניות.
|
|
עכשיו תורך: תלמיד רצה לחשב את הממוצע השנתי שלו בהיסטוריה, ציוני המבחנים שלו היו:
|
(לאחר שתלמד פלט וקלט, תדע גם כיצד להדפיס את התוצאה (ראה תרגיל זה).)
הפתרון
int main()
{
/* The given data */
unsigned int grade1 = 78, grade2 = 84, grade3 = 45, grade4 = 97, grade5=64;
float average;
average = (grade1 + grade2 + grade3 + grade4 + grade5) / 5; /* finding the average */
return 0;
}
קלט ופלט[]
אפשר להשתמש במשתנים כדי לשמור קלט שהקלידה המשתמשת. כמו כן, ניתן להדפיס כפלט את ערכו של כל משתנה. נעסוק בכך בפלט וקלט.
אורך החיים וטווח ההכרה של משתנים[]
לא בכל מקום אפשר להצהיר על משתנים, ולא בכל מקום אפשר להשתמש במשתנים שכבר הוצהרו. לפני שנראה את החוקים לכך, נבין קודם מספר מושגים בסיסיים יותר.
רצפי פקודות[]
נתבונן בשורות הבאות:
int a, int b;
a = 3;
b = 7 + 8;
זהו רצף פקודות. כאשר תרוץ התוכנית, קודם תתבצע השורה הראשונה (המצהירה על שני משתנים שלמים), לאחר מכן השורה הבאה, וכולי. היות שמדובר ברצף, משתנה יכול להשתמש במשתנים שכבר הוצהרו:
int a = 3;
int b = a + 8;
בלוקים[]
בלוק הוא רצף פקודות בתוך סוגריים מסולסלים. להלן בלוק בעל שתי פקודות:
{
a = 3;
b = 7 + 8;
}
אין הגבלה על מספר הפקודות היכולות להופיע בבלוק; בלוק יכול להיות ריק, או להכיל עשרות פקודות. להלן בלוק ריק (בעל 0 פקודות) שלאחריו הבלוק שכבר ראינו:
{
}
{
a = 3;
b = 7 + 8;
}
בלוק יכול אפילו להכיל בלוק אחר:
{
e = -3;
{
a = 3;
b = 7 + 8;
}
d = 16;
}
בלוקים מהווים דרך לציין למהדר שרצף של פקודות מאוגד ליחידה אחת. בהמשך, כשנדבר על תנאים, לולאות, ופונקציות נבין את ההגיון בכך, אך כעת מספיק שנהיה מודעים לקיומם של בלוקים.
משתנים לוקליים[]
משתנה לוקלי הוא משתנה המוגדר בתוך בלוק כלשהו. כאן, לדוגמה, a הוא משתנה לוקלי:
{
int a;
a = 3;
}
בתוכנית C, בדרך כלל רוב המשתנים הם לוקליים. המשתנה מוגדר מיד בשורה המצהירה עליו, והוא "מוּכָּר" לאורך כל הבלוק (כלומר, ניתן להכניס אליו ערכים או להשתמש בערכו לאורך כל הבלוק). כאשר מסתיים הבלוק, המשתנים שהוגדרו בו אינם מוכרים יותר ע"י התוכנית, והזיכרון שהוקצה להם מוחזר למערכת (חריגים מכלל זה הם משתנים שהוקצה להם זיכרון באופן דינמי. על כך יפורט בפרק ניהול זיכרון דינאמי.) קטע הקוד הבא, לדוגמה, שגוי:
{
int n = 2;
}
{
int x;
x = n + 5; /* ERROR! variable "n" is not recognized here! */
}
דוגמה זו מסבירה את כינויים של משתנים אלה כלוקליים (כלומר מקומיים). הם מוכרים אך ורק במקומם - בתוך הבלוקים בהם הם הוגדרו. כאן נובע, בין היתר, שבשני בלוקים שונים ניתן להגדיר שני משתנים בעלי שם זהה. כל אחד מהם יוכר רק בתחום הבלוק שלו, ולכן לא תהיה בכך התנגשות. לדוגמה:
{
int n = 2;
}
{
int n = 3;
int x = n + 5; /* OK! */
}
בדוגמה זו כל אחד מהבלוקים מכיל משתנה בשם n. כיוון שהם לוקליים, אין ביניהם כל קשר ולכן אין עם זה בעיה. במקרה זה, אגב, המשתנה x בבלוק השני יקבל ערך 8.
|
|
שימו לב: מהדרים מיושנים יחסית דורשים שמשתנה לוקלי יוצהר בתחילת בלוק בלבד. שפת C במקור דרשה זאת, אך הדבר שונה בתקן C99. |
משתנים גלובליים[]
ניתן להגדיר משתנים גם מחוץ לכל בלוק שהוא. משתנים כאלו יהיו גלובליים, ויוכרו ע"י כל הפונקציות שנמצאות באותו קובץ. בקוד הבא, לדוגמה, x הוא משתנה גלובלי:
char x;
int main()
{
int n;
n = 3;
x = 'f';
return 0;
}
|
|
כדאי לדעת: בדרך כלל מומלץ להמנע משימוש במשתנים גלובליים. |
המחסנית[]
|
|
שקול לדלג על נושא זה מומלץ לשקול לדלג על נושא זה בפעם הראשונה בה נתקלים בו, ולחזור אליו רק לאחר מעבר כללי על כל הספר. |

פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
משתנים קבועים[]
|
|
שקול לדלג על נושא זה בקריאה ראשונה של ספר זה תוכל לדלג על נושא זה. ההסבר עושה שימוש בתנאים. תוכל לחזור לכאן כשתגיע למצביעים או לקדם מעבד, או אם אתה נתקבל בהמשך במילה השמורה const. |
לפעמים מגדירים משתנים כמשתנים קבועים, או משתנים שאסור לשנות את ערכם. עושים זאת בצורה הבאה:
const <type> <name>
המהדר יאכוף זאת. לדוגמה, בקטע הקוד הבא:
const int a = 8;
/* Error: can't change the value of a const variable! */
a = 7;
המהדר יתלונן על הניסיון להשים ערך חדש בa.
משתנים קבועים נועדו להגן עלינו, המתכנתים, מפני שגיאות אפשריות בקוד. הדוגמאות הבולטות לכך הן במצביעים (נושא שאותו נלמד בהמשך), אך הנה דוגמה דרמטית פחות שאינה משתמשת בהם. קטע הקוד הבא מחשב את ממוצע משוקלל מתוך שני משתנים (midterm_grade וfinal_grade), ומבצע פעולות בהתאם לשאלה האם הממוצע פחות מ60 או בדיוק 60:
int average = 0.1 * midterm_grade + 0.9 * final_grade;
if(average < 60)
...
else if(average = 60) /* This line is suspicious! */
...
אפשר לראות שאחת השורות שגוייה. השורה:
else if(average = 60)
משימה את הערך 60 למשתנה average, ולא בודקת שוויון; מדובר בשגיאת תכנות. לו היינו מגדירים את המשתנה כקבוע, עם זאת, כך:
const int average = 0.1 * midterm_grade + 0.9 * final_grade;
המהדר היה מתלונן על הנסיון לשנות את ערכו בבדיקת התנאי השגויה.
שמות נרדפים לטיפוסים בעזרת typedef[]
|
|
שקול לדלג על נושא זה השימוש בנושא זה מרוכזים פחות או יותר במצביעים, מבנים, ואיגודים. |
שפת C מאפשרת להגדיר "שם נרדף" לטיפוסים. עושים זאת בצורה:
typedef <known_type> <alias>;
כאשר known_type הוא טיפוס משתנה ידוע, וalias הוא "שם נרדף" לו.
לדוגמה, אפשר לתת "שם נרדף" לשלם, ולהשתמש בו להצהרה על משתנים:
typedef int my_new_name_for_int;
my_new_name_for_int x = 3;
הסבה[]
|
|
שקול לדלג על נושא זה מומלץ לשקול לדלג על נושא זה בפעם הראשונה בה נתקלים בו, ולחזור אליו רק לאחר מעבר כללי על כל הספר. |
לעיתים קרובות נצטרך לעבור בין טיפוסים (סוגים) של משתנים. פעולת ההסבה מכונה Casting, והיא נמצאת בשימוש נרחב.
דוגמה: פונקצית sqrt המשמשת להוצאת שורש, פועלת על טיפוס נקודה צפה בלבד, ואילו פעולת חשבון % (מודולו) פועלת על טיפוס שלם בלבד. אם נרצה להשתמש בפונקציות האלה עם משתנים מסוגים אחרים - נצטרך להסב אותם קודם.
ביצוע ההסבה[]
כדי להסב ערך כותבים בסוגריים, לפני הערך עצמו, את סוג הטיפוס אליו רוצים להסב. דוגמה: נניח שיש לנו מספר שלם ונרצה להכניס אותו למשתנה מסוג float, אז נכתוב את הקוד הבא:
float x = (float) 1;
ניתן לבצע זאת גם עם משתנים:
int i = 121;
char *x = (char *) i;
אלו הן דוגמאות חסרות תועלת במרבית המקרים, אך חוקיות לשימוש.
הסבה אוטומטית וסכנת אובדן המידע[]
נשים לב שבמרבית המקרים הסבות כמו שראינו קודם הן מיותרות: כמעט בכל מצב בו נזדקק להסבה של סוגי משתנים פשוטים, המהדר ידע לבצע זאת באופן עצמאי. למשל, חוקי (ונפוץ) להמיר int ל-float בצורה הבאה:
int a = 1;
float b = a;
שימו לב: לעיתים קרובות הפעולה הזו כרוכה באובדן מידע. אם, לדוגמה, נמיר את המספר 1.234 (שהוא עשרוני) ל-int, נקבל 1, ולא נוכל לשחזר את המספר המקורי. הרעיון פשוט: אם מסבים משתנה אל סוג אחר שיכול להכיל פחות מידע - המידע הנוסף יקוצץ. ניתן לראות זאת בדוגמה הבאה:
#include <stdio.h>
int main() {
double a = 7.654321;
int b;
printf("Before: %lf\n", a);
b = (int) a;
a = (double) b;
printf("After: %lf\n", a);
return 0;
}
כל מה שהיה במשתנה a אחרי הנקודה אבד כתוצאה מההסבה, אפילו שהסבנו את אותו הערך בדיוק חזרה ל-double.
קריאה לפונקציה עם הסבה[]
מקרה נפוץ בו נזדקק להסבה הוא קריאה לפונקציות שדורשות סוג מסויים של משתנים. אם, למשל, נרצה לקרוא לפונקציה sqrt עם מספרים שלמים, נצטרך להסב אותם קודם. צורת הכתיבה היא כזאת:
#include <stdio.h>
#include <math.h>
int main() {
int a = 16;
double b;
b = sqrt((double) a);
printf("Square root of %d: %d\n", a, (int) b);
return 0;
}
הסבה לא חוקית[]
הסבה היא חוקית בין משתנים פשוטים, אך בדרך כלל איננה חוקית עם סוגים אחרים. הדוגמה הבאה מראה שתי הסבות לא חוקיות:
struct my_struct {
int x;
};
int main() {
int a = 16;
struct my_struct b;
b = (struct my_struct) a; // Illegal
a = (int) b; // Illegal
return 0;
}
משתנים סטטיים[]
|
|
שקול לדלג על נושא זה מומלץ לשקול לדלג על נושא זה בפעם הראשונה בה נתקלים בו, ולחזור אליו רק לאחר מעבר כללי על כל הספר. |
כל משתנה, לוקלי או גלובלי, ניתן להגדרה כמשתנה סטטי. יש לכך שתי משמעויות שונות לחלוטין. נדון בכך כשנדבר על פונקציות ועל מודולים.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
תרגילים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
טיפוסי משתנים[]
בחירת טיפוסים נכונה[]
נניח שאתה צריך שני משתנים: אחד, בשם grade שיתאר ציון מבחן, והשני, בשם length, שיתאר אורך קרש. להלן תוכנית המצהירה על כך:
int main()
{
unsigned int grade;
float length;
return 0;
}
נשים לב שלמשתנה הראשון בחרנו בטיפוס שלם ללא סימן, ולשני בחרנו משתנה נקודה צפה.
כתוב תוכנית שתכיל הצהרות למשתים הבאים:
- משתנים לציונים, grade_1, grade_2, וgrade_3.
- משתנה לממוצע ציונים, grade_average.
- משתנה לזווית, angle.
פתרון
int main()
{
unsigned int grade_1 ,grade_2 ,grade_3;
float grade_average;
float angle;
return 0;
}
שמות משתנים[]
החלט האם כל אחד מהשמות הבאים מתאים להיות שמו של משתנה. אם לא, הסבר מדוע: להלן פירוט:
- hello
- 2hello
- hello2
- hello_2
- hello-5
- my var
פתרון
להלן פירוט:
- מותר
- אסור - לשם משתנה אסור להתחיל במספר
- מותר
- מותר
- אסור - שם חשתנה אינו יכול להכיל את התו '-'
- אסור - שם משתנה אינו יכול להכיל רווח
עבודה עם משתנים[]
הצהרה והשמה בשלמים[]
כתוב תוכנית שתצהיר על משתנה שלם (int) בשם a, לאחר מכן תשים אליו את הערך 7, ולאחר מכן תשים אליו את הערך 9.
פתרון
int main()
{
int a;
a = 7;
a = 9;
return 0;
}
הצהרה, אתחול, והשמה בשלמים[]
כתוב תוכנית שתצהיר על משתנה שלם (int) בשם a, תאתחל אותו לערך 7, ולאחר מכן תשים אליו את הערך 9.
פתרון
int main()
{
int a = 7;
a = 9;
return 0;
}
הצהרה והשמה במספרי נקודה צפה[]
כתוב תוכנית שתצהיר על משתנה נקודה צפה (float) בשם pi, ותשים אליו את הערך 3.1416.
פתרון
int main()
{
float pi;
pi = 3.1416;
return 0;
}
אורך החיים וטווח ההכרה של משתנים[]
סווג משתנים לגלובליים ולוקליים[]
התבונן בתכנית הבאה:
int x
int main()
{
int a;
a = 3;
{
int b;
}
{
{
int c = 5;
}
}
}
- כמה משתנים לוקליים וכמה משתנים גלובליים יש בתכנית?
- לכמה בלוקים שייך המשתנה c?
הפתרון
לפי הכללים שראינו באורך החיים וטווח ההכרה של משתנים:
- כל אחד מa, b, וc נמצאים בין סוגריים מסולסלים. הם חלק מבלוקים, ולכן משתנים לוקליים. x אינו חלק מאף בלוק, ולכן הינו משתנה גלובלי.
- המשתנה c שייך ל3 בלוקים.
פלט וקלט
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
פלט וקלט הם מהרכיבים הבסיסיים בכל תוכנה, ומאפשרים קשר בין המשתמש לבין התוכנה. הפלט מאפשר לתוכנית להוציא מידע אל המשתמש, והקלט מאפשר לתוכנה לקלוט מידע שמוכנס על ידי המשתמש.
|
|
כדאי לדעת: קטעי הקוד שבפרק זה משתמשים בספרייה הסטנדרטית. נדון בספריות באופן מעמיק יותר כאן. לעת עתה, פשוט יש לזכור לרשום בראשי הקבצים המשתמשים בקטעי הקוד שבפרק זה#include <stdio.h> כפי שראינו בשורה 1 של שלום עולם!. |
פונקציית הפלט printf[]
אחת הפונקציות החשובות ביותר בשפת C היא printf, המאפשרת להדפיס הודעות על מסך המחשב לפי תבנית (format בלעז) נתונה (ומכאן שמה, print format).
הדפסת הודעות קבועות[]
printf מאפשרת להדפיס הודעות קבועות (כפי שכבר ראינו). לדוגמה, כדי להציג hello world, אפשר לכתוב:
printf("Hello world");
|
|
כדאי לדעת: שפת C גם כוללת מספר תווים מיוחדים, לדוגמה התו'\n' שהוא התו ירידת שורה (כלומר, סיום השורה הנוכחית ומעבר לשורה חדשה). לדוגמה, הקריאה הבאה:
printf("Hello world\n");
|
הדפסת ערכים בעזרת מציינים[]
printf מאפשרת גם להדפיס ערכי משתנים. לדוגמה, אם x הוא משתנה מטיפוס שלם, אז קטע הקוד הבא:
printf("the value is %d", x);
ידפיס the value is ולאחריו הערך בx. כלומר, רצף התווים %d משמעו כאן מציין שיש להדפיס ערך מטיפוס שלם.
אם רוצים להדפיס ערך שאינו דווקא מטיפוס שלם, יש להחליף את רצף התווים %d ברצף שמתאים לטיפוס:
- c% עבור טיפוסים מסוג char
- f% עבור טיפוסים מסוג float
- lf% עבור טיפוסים מסוג double
- e% כדי להדפיס מספרים בתצוגת נקודה צפה, כלומר 1000 יודפס כ-1e3, ו- 0.001 יודפס 1e-3, וכן הלאה. נוח לעבודה עם מספרים גדולים או קטנים במיוחד.
- s% עבור מחרוזות (שטרם למדנו בנקודה זו)
- p% עבור מצביעים (שטרם למדנו בנקודה זו)
הפונקציה printf אף מאפשרת להדפיס יותר מערך יחיד. להדפסת שני ערכים, לדוגמה, אפשר לכתוב:
printf("the values are %d %d", x, y);
דגלים, קובעי רוחב ודיוק[]
|
|
שקול לדלג על נושא זה נושא זה מסביר כיצד לשלוט בצורה מדוייקת מאד בפלט, דבר שאינו דרוש לרוב. בנוסף, הנושא מניח שהנך מכיר מחרוזות. |
עד עתה השתמשנו במציינים כך:
%<specifier>
כאשר specifier הוא מציין הטיפוס. כעת נראה כיצד לשלוט בצורה מדוייקת יותר בפלט.
קובעי רוחב[]
לפני המציין, אפשר אופציונאלית לכתוב גם קובע רוחב, כך:
%[width]<specifier>
כאשר specifier הוא המציין, וwidth הוא קובע הרוחב.
אם width הוא מספר, אז הדפסת הערך תיקח לכל הפחות width תווים. לדוגמה:
printf("%10d", 3)
תדפיס:
3
כך מאפיינים גם רוחב הדפסה למחרוזות. לדוגמה:
printf("%10s", "ׁHello")
תדפיס:
Hello
קובעי דיוק[]
לפני המציין, אפשר אופציונאלית לכתוב גם קובע דיוק, כך:
%[.precision]<specifier>
כאשר specifier הוא המציין, וprecision הוא קובע הדיוק.
אם precision הוא מספר, אז דיוק המספר יהיה בדיוק precision תווים. לדוגמה:
printf("%.3f\n", 3.14159265);
printf("%.3f\n", 3.1);
ידפיסו:
3.142
3.100
אפשר להפעיל זאת גם על מחרוזות. לדוגמה:
printf("%.3s\n", "Hello");
תדפיס:
Hel
אפשר להשתמש בו זמנית בקובעי רוחב ודיוק, בצורה:
%[width][.precision]<specifier>
במקרה כזה, קודם יופעל קובע הדיוק, ולאחריו קובע הרוחב. לדוגמה:
printf("%10.3f\n", 3.14159265);
printf("%10.3f\n", 3.1);
printf("%10.3s\n", "Hello");
ידפיסו:
3.142
3.100
Hel
דגלים[]
לפני המציין, אפשר אופציונאלית לכתוב גם דגלים, כך:
%[flags]<specifier>
כאשר flags הם דגלים, וspecifier הוא מציין.
הדגלים הם:
| דגל | משמעות |
|---|---|
| - | במקרה שצויין קובע רוחב, והערך המודפס צר יותר, הצמד לצד שמאל (ברירת המחדל הוא צד ימין). |
| + | הצמד לפני מספרים חיוביים את התו '+' (ברירת המחדל היא לכתוב מספרים חיוביים ללא סימן). |
| (רווח) | הצמד לפני מספרים חיוביים את התו ' '. |
| # | הוסף עוד תווים לאחידות פלט, לדוגמא התו '.' לאחר מספרי נקודה צפה שערכם שלם. |
| 0 | במקרה שצויין קובע רוחב, והערך המודפס צר יותר, כתוב אפסים משמאל למספר. |
אפשר להשתמש בו זמנית בדגלים, קובעים, ומציינים, בצורה הבאה:
%[flags][width][.precision]<specifier>
פונקציות הקלט scanf[]
בת זוגה של printf היא scanf, המאפשרת לקלוט ערכים לפי פורמט נתון.
קליטת ערכים בעזרת מציינים[]
לאחר שמצהירים על משתנה, אפשר לקלוט ערכים לתוכו. לדוגמה:
int x;
scanf("%d", &x);
כאשר התוכנית תגיע לשורה זו, היא תמתין עד שהמשתמש יקליד מספר וילחץ Enter. המספר ייקלט למשתנה x.
|
|
כדאי לדעת: יש לשים לב לסימן & המופיע לפני המשתנה. סימן זה מציין את כתובתו של המשתנה, ונלמד את משמעותו כשנגיע למצביעים. לעת עתה אפשר להתעלם ממשמעותו, ורק להקפיד לרשום אותו לפני המשתנה בscanf. |
באותו האופן, נוכל לקלוט מספר משתנים מסוגים שונים:
int number;
char first_letter;
int phone;
printf("Please enter a number, first character of your name, and your phone number:\n");
scanf("%d %c %d", &x, &first_letter, &phone);
בדוגמה זו יקבל המשתמש בקשה לכתוב מספר, תו משמו ואת מספר הטלפון שלו. לאחר שיזין פרטים אלה, הם ייקלטו במשתנים.
קובעי רוחב[]
|
|
שקול לדלג על נושא זה נושא זה מסביר כיצד לשלוט בצורה מדוייקת מאד בקלט, דבר שאינו נצרך לרוב. הדבר שימושי בעיקר בפלט וקלט קבצים ובמחרוזות. |
לפני המציין, אפשר אופציונאלית לכתוב גם קובע רוחב, כך:
%[width]<specifier>
כאשר specifier הוא המציין, וwidth הוא קובע הרוחב.
אם width הוא מספר, אז ייקלטו לכל היותר width תווים. לדוגמה:
scanf("%3d", &num)
תקלוט לכל היותר 3 תווים. כך מאפיינים גם רוחב קליטה למחרוזות. לדוגמה:
char a[5];
scanf("%4s", a);
תקלוט לכל היותר 4 תווים למחרוזת a.
קליטת מחרוזות קבועות[]
|
|
שקול לדלג על נושא זה נושא זה מסביר כיצד לשלוט בצורה מדוייקת מאד בקלט, דבר שאינו נצרך לרוב. הדבר שימושי בעיקר בפלט וקלט קבצים. |
נניח שאנו רוצים לקלוט שני מספרים, כל אחד בעל 5 ספרות. נוכל לכתוב זאת כך:
int x, y;
scanf("%5d %5d", &x, &y);
נשים לב שיקלטו שני מספרים שביניהם רווח אחד או יותר.
עתה נניח שאנו רוצים לקלוט שני מספרים, כל אחד בעל 5 ספרות, מופרדים על ידי פסיק. נוכל לכתוב זאת כך:
int x, y;
scanf("%5d,%5d", &x, &y);
כלומר, צריך לשים פסיק במחרוזת התבנית. אם המשתמש אכן יקליד שני מספרים מופרדים על ידי פסיקים, ייקלטו המספרים בx וy, והפונקציה תחזיר 2. אם לא, הפוקנציה תחזיר מספר קטן מ2.
נוכל להכליל זאת:
- אם מופיע תו שאינו רווח במחרוזת התבנית, הקלט ימשיך רק אם המשתמשת תקליד תו זה בדיוק.
- הפונקציה scanf מחזירה את מספר המשתנים שהצליחה לקלוט.
פונקציות פלט/קלט נוספות[]
אם כי הפונקציות printf וscanf הן השימושיות ביותר, ישנן עוד פונקציות לקלט ופלט:
- בפלט וקלט קבצים נראה פונקציות לקריאה וכתיבה לקבצים.
- בפלט וקלט מחרוזות נראה פונקציות לפלט וקלט מחרוזות.
- הספריה הסטנדרטית כוללת פונקציות נוספות לקלט ופלט.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
תרגילים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
קליטת והדפסת גיל משתמש[]
כתוב תכנית שתבקש מהמשתמש את גילו, תשמור את הקלט במשתנה, ותדפיס הודעת אישור הכוללת את גילו.
ראשית, על התוכנית להדפיס את ההודעה הבאה:
Please enter your age:
לאחר שיקליד המשתמש את גילו, על המסך להראות דומה לכך:
Please enter your age: 23
כעת תדפיס התוכנית הודעת אישור לגיל:
You are 23 years old.
הפתרון
#include <stdio.h>
int main()
{
unsigned int age;
printf ("please enter youre age: ");
scanf ("%d", &age);
printf ("You are %d years old.\n", age);
return 0;
}
קליטת והדפסת שם וגיל משתמש בשני שלבי קלט[]
כתוב תכנית שתבצע את הפעולות הבאות בסדר הבא:
- תבקש מהמשתמש את האות הראשונה של שמו, ותשמור את הקלט במשתנה
- תבקש מהמשתמש את גילו, ותשמור את הקלט במשתנה
- תדפיס הודעת אישור הכוללת את שמו ואת גילו של המשתמש
ראשית, על התוכנית להדפיס את ההודעה הבאה:
Please enter the first letter of your name:
לאחר שיקליד המשתמש את האות הראשונה של שמו, על המסך להראות דומה לכך:
Please enter the first letter of your name: H
כעת, על התוכנית להדפיס את ההודעה הבאה:
Please enter your age:
לאחר שיקליד המשתמש את גילו, על המסך להראות דומה לכך:
Please enter the first letter of your name: H
Please enter your age: 23
כעת תדפיס התוכנית הודעת אישור לשם ולגיל:
Your name begins with H and you are 23 years old.
הפתרון
#include <stdio.h>
int main()
{
char name;
int age;
printf("please enter the first letter of your name: ");
scanf("%c", &name);
printf("please enter your age: ");
scanf("%d", &age);
printf("your name begins with %c and you are %d years old\n", name, age);
return 0;
}
קליטת והדפסת שם וגיל משתמש בשלב קלט אחד[]
כתוב תכנית שתבצע את הפעולות הבאות בסדר הבא:
- תבקש מהמשתמש את האות הראשונה של שמו ואת גילו, ותשמור את הקלטים במשתנים
- תדפיס הודעת אישור הכוללת את האות הראשונה של שמו ואת גילו של המשתמש
ראשית, על התוכנית להדפיס את ההודעה הבאה:
Please enter your first letter of your name and your age:
לאחר שיקליד המשתמש את שמו, על המסך להראות דומה לכך:
Please enter your first letter of your name and your age: H 23
כעת תדפיס התוכנית הודעת אישור לשם ולגיל:
Your name begins with H and you are 23 years old.
|
|
שימו לב: השתמש בפקודת printf יחידה ופקודת scanf יחידה בתרגיל זה. |
הפתרון
#include <stdio.h>
int main()
{
int age;
char letter;
printf ("please enter the first letter of your name, and your age: ");
scanf("%c %d", &letter, &age);
printf("your name begins with %c and you are %d years old\n", letter, age);
return 0;
}
פעולות חשבוניות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
דף זה מסביר את פעולות החשבון הבסיסיות שהן חלק מהשפה. שפת C קטנה מאד, וכוללת את פעולות החשבון הבסיסיות ביותר (כמו חיבור או כפל). פעולות חשבוניות מתקדמות יותר, לדוגמה פעולות טריגונומטריות, אינן חלק מהשפה אלא שייכות לספריות השפה.
הפעולות הבסיסיות[]
שפת C מאפשרת לחבר (ע"י +), לחסר (ע"י -), להכפיל (ע"י *), לחלק (ע"י /), ולמצוא שארית (ע"י %). להלן מספר דוגמאות:
int x = 4, y = 2;
/* Prints 4 + 2 = 6 */
printf("%d + %d = %d\n", x, y, x + y);
/* Prints 4 - 2 = 2 */
printf("%d - %d = %d\n", x, y, x - y);
/* Prints 4 * 2 = 8 */
printf("%d * %d = %d\n", x, y, x * y);
/* Prints 4 / 2 = 2 */
printf("%d / %d = %d\n", x, y, x / y);
אפשר לבצע פעולות חשבוניות על מספרים, משתנים, או כל שילוב של משתנים ומספרים:
int x = 2, y = 3;
/* Prints 13 */
printf("%d\n", x + y + 3 + 5);
סדר פעולות החשבון[]
סדר פעולות החשבון בשפת C הוא המקובל באלגברה בסיסית, ולכן כפל (*), לדוגמה, מבוצע לפני חיבור (+). השורה הבאה, לדוגמה, תדפיס 17:
printf("%d\n", 2 + 3 * 5);
בדיוק כבאלגברה בסיסית, ניתן להשתמש בסוגריים כדי לציין סדר פעולות שונה. השורה הבאה, לדוגמה, תדפיס 25:
printf("%d\n", (2 + 3) * 5);השמת ערכים[]
השמה ואתחול[]
כפי שראינו במשתנים, אפשר להשתמש בסימן = להשמה ואתחול.
int x = 2, y = 3;
int z = x + y + 5;חשוב להבין מה קורה כאן בשורה השניה. ראשית מעריכים את הביטוי x + y + 5 (ערכו כאן 10). משימים ערך זה למשתנה z. אפשר גם להשים למשתנה ערך חדש שתלוי בערכו הקודם. נתבונן לדוגמה בשורה
x = x + 2;הכוונה איננה למשוואה אלגברית על x (שאגב, נטולת פתרון). הכוונה היא להעריך את ערכו של הביטוי x + 2, ולהשים ערך זה חזרה לx (דבר זה ידרוס את הערך הקודם).
סימני קיצור בהשמה עצמית[]
כפי שראינו:
x = x + 2;משמעו השמה עצמית של x לערכו הקודם ועוד משהו (2 במקרה זה). בפועל, סוג זה של השמה עצמית נפוץ מאד. שפת C ידועה בקצרנותה הרבה לביטויים נפוצים. אפשר לכתוב את הביטוי הקודם גם באופן הבא, הקצר יותר:
x += 2;המשמעות כאן זהה לחלוטין: מעריכים את x + 2, ומשימים את הערך לx.
שפת C כוללת סימונים מקוצרים להשמות עצמיות לכל חמש פעולות החשבון הבסיסיות:
/* x = x + 1 */
x += 1;
/* y = y - 3 */
y -= 3;
/* z = z * 8 */
z *= 8;
/* w = w / 4 */
w /= 4;
/* p = p % 2 */
p %= 2;הגדלה עצמית והקטנה עצמית[]
הגדלה עצמית[]
נניח שאנו רוצים לקדם את x ב1. כבר ראינו שאפשר לרשום זאת כך:
x = x + 1או, באופן קצר יותר, כך:
x += 1;כשנגיע ללולאות, נראה שהגדלה עצמית של משתנה דווקא ב-1 (כלומר, שהמשתנה מקבל את ערכו הקודם ועוד 1) היא פעולה נפוצה במיוחד. פעולה זו, הגדלה עצמית (increment) יכולה להיכתב כך:
x++;או כך:
++x;(נעמוד על ההבדלים בין שתי הצורות בהגדלה עצמית והקטנה עצמית לכתחילה ובדיעבד.)
הקטנה עצמית[]
באותו אופן כהגדלה עצמית, ניתן להוריד 1 מערך משתנה כך:
x--;או כך:
--x;הגדלה עצמית והקטנה עצמית לכתחילה ובדיעבד[]
לעתים, קיים ביטוי בו משתנה הן מקודם והן מוערך. נניח, לדוגמה, שx מכיל את הערך 3, ונתבונן בשורה:
z = x++;שני דברים מתבצעים כאן:
- x מקודם ב1
- z מקבל ערך כלשהו
השאלה היא, אבל, מה קודם למה. אם קודם x מקודם, אז בסיום השורה z יכיל את הערך 4. מצד שני, אם קודם z מקבל ערך, אז בסיום השורה z יכיל את הערך 3 (כי x קודם ל4 רק אחרי שz קיבל את ערכו הקודם). לצורך כך מכילה שפת C הן הגדלה עצמית לכתחילה, והן הגדלה עצמית בדיעבד. משמעות הגדלה עצמית בדיעבד (post-increment)
x++היא הערך את x ורק אז קדם אותו. לעומת זאת, משמעות הגדלה עצמית לכתחילה (pre-increment)
++xהיא קדם את x והערך את התוצאה. הדבר דומה להקטנה עצמית בדיעבד (post-decrement)
x--לעומת הקטנה עצמית לכתחילה (pre-decrement)
--xפעולות חשבוניות על שלמים ונקודות צפות[]
אלגברה וחישובים שלמים[]
כבר ראינו במשתנים על ההבדלים בין שלמים לנקודות צפות. כדאי לשים לב לנקודה, שכן בלעדיה נוכל לקבל תוצאות מפתיעות. נתבונן בקטע הקוד הבא:
int x = 3, y = 8;
printf("The average is %f\n", (x + y) / 2);אם נהדר ונריץ את הקוד, נראה שהממוצע המודפס הוא 5.0000, ולא 5.5 = (3 + 8) / 2 כפי שהיינו מצפים בצורה אלגברית.
מדוע הדבר קורה? בשפת C, כל פעולה על טיפוסים שלמים מניבה תמיד תוצאה מסוג שלם. סדרת הפעולות המתבצעת כאן היא זו:
- (x + y) פועלת על מספרים שלמים (שכן הן x והן y הם שלמים), ולכן התוצאה מסוג שלם.
- (x + y) / 2 פועלת על שלמים (כבר ראינו ש(x + y) היא שלם, ו2 הוא שלם), ולכן התוצאה מסוג שלם.
- המספר השלם 5 מומר למספר הצף 5.0000 ומודפס.
המרות[]
לעתים אנו מחזיקים ערך, נניח 3, המיוצג כטיפוס כלשהו (נניח char), אך משום מה יש להמיר ערך זה לטיפוס אחר (נניח int). מה קורה במקרה זה? הדבר תלוי בשאלה האם מידע אובד פוטנציאלית, או לא.
המרות מרחיבות[]
נתבונן בקטע הקוד הבא:
char x = 3;
int y = x;בשורה הראשונה מושם הערך 3 למשתנה x, שהוא מסוג תו. השורה הבאה משימה את ערכו של x לתוך המשתנה y, שהוא מסוג שלם. האם מידע יכול לאבוד כאן? לא, מפני שתחום הערכים שיכול להכיל int כולל את תחום הערכים שיכול להכיל char. המרה זו נטולת בעיות, מפני שאנו ממירים ערך במשתנה בעל תחום קטן, במשתנה בעל תחום רחב יותר.
באותו אופן, ובדיוק מאותה סיבה, אין בעיה בהמרה מint לfloat, לדוגמה.
המרות מצרות[]
נתבונן בקטע הקוד הבא:
int x = 3;
char y = x;כאן יש בעיה פוטנציאלית, משום שאנו ממירים ערך במשתנה בעל תחום גדול, במשתנה בעל תחום צר יותר. חלק מהמידע ילך לאיבוד.
חישובים מעורבים[]
כאשר המהדר מבצע חישובים על מספר ערכים מסוגים שונים, הוא עורך המרות מרחיבות במידת הצורך עד שהחישוב פועל על ערכים מאותו סוג. לדוגמה, נתבונן בקטע הקוד הבא:
int x = 2, y = 3;
printf("The average is %f\n", (x + y) / 2.0);קטע קוד זה מדפיס שהממוצע הוא 2.5, כנדרש. היות ש2.0 הוא משתנה נקודה צפה, המהדר יבצע המרה מרחיבה כך שx + y יהיה נקודה צפה, על אף שהן x והן y שלמים (ועל כן סכומם אמור היה להיות שלם).
דוגמה: המרה בין סוגי מעלות שונים[]
להלן דוגמה פשוטה מאד, שבה נשתמש גם בלולאות ופונקציות.
נניח שc מייצג טמפרטורה נתונה במעלות בשיטת Celsius, ואנו רוצים למצוא את f, המעלות בשיטת Fahrenheit. על פי נוסחה ידועה, f הוא 9 / 5 * c + 32. נניח גם שהדיוק אינו חשוב לנו במיוחד, ואנו מוכנים לעבוד במספרים שלמים (על אף שגיאת העיגול). להלן תכנית המקבלת כקלט מעלה בFahrenheit, ומדפיסה אותו בCelsius:
#include <stdio.h>
int main()
{
int c, f;
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
f = 9 / 5 * c + 32;
printf("This is %d in Fahrenheit\n", f);
return 0;
}להפתעתנו (או לא), התוכנית פשוט תפלוט תמיד את c + 32, שהיא שגיאה שחורגת בהרבה מסתם שגיאת עיגול. מדוע הדבר קורה? ראינו בפעולות חשבוניות על שלמים ונקודות צפות שכל פעולה על טיפוסים שלמים מניבה תמיד תוצאה מסוג שלם. 9 / 5, לכן, מתורגם ל1, ולכן מקבלים 1 * c + 32 בפועל.
נוכל לתקן זאת על ידי כך שנחליף את 9 / 5 ב1.8, שהוא מספר נקודה צפה:
f = 1.8 * c + 32;כעת מדובר בחישוב מעורב, והשלמים בצד ימין של הסימן = יומרו במספרי נקודה צפה. לאחר החישוב, הערך יושם בf שהוא מספר שלם, ורק החלק העשרוני יאבד (כלומר, נקבל רק שגיאת עיגול).
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
ביטויים בוליאניים ותנאים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
כדי להשתמש בנתונים שנקלטו מהמשתמש ולנתב בעזרתם את התוכנה, מדי פעם צריכים לעשות בדיקה של הנתונים.
ערכים בוליאניים[]
אמת ושקר, וייצוגם בשפת C[]
ביטוי בוליאני הוא ביטוי שיכול לקבל את הערכים "אמת" ו"שקר". לעתים צריך בתכניות מחשב להכריע האם דבר הוא אמת או שקר, לדוגמה, האם נכון שערכו של המשתנה x הוא 6, או האם שקר הוא שערכו של המשתנה x קטן מערכו של המשתנה y.
בשפת C נהוגה המוסכמה שהערך המספרי 0 מציין "שקר", וכל ערך אחר מציין "אמת". בהמשך דף זה ובלולאות נראה כיצד לגרום למחשב לבצע פעולות שונות בהתאם לשאלה האם ערך כלשהו הוא אמת או שקר.
אופרטורים בוליאניים[]
שפת C כוללת מספר אופרטורים בוליאניים, כלומר אופרטורים שתוצאתם היא "אמת" או "שקר". לדוגמה, כדי לבדוק האם ערך המשתנה x הוא 6, רושמים
x == 6כאשר יתבצע קטע קוד זה, יתרגם אותו המחשב ל"אמת" (ערך כלשהו שאינו 0) אם ערך x אכן 6, או ל"שקר" (הערך המספרי 0) אם ערכו שונה.
שים לב להבדל בין האופרטור == לבין פעולת ההשמה =.
לשפת C האופרטורים הבוליאניים הבאים:
- == (להבדיל מ= המשמש להשמה) - האם שני צדי הביטוי שווים
- =! - האם שני צדי הביטוי שונים
- > - האם הצד הימני של הביטוי גדול מצדו השמאלי
- < - האם הצד הימני של הביטוי קטן מצדו השמאלי
- => - האם הצד הימני של הביטוי גדול או שווה לצדו השמאלי
- =< - האם הצד הימני של הביטוי קטן או שווה לצדו השמאלי
תוכל לראות כיצד משתמשים באופרטורים בוליאניים בהתנאי if (ייתכן שתרצה לבדוק זאת בקצרה לפני המעבר לנושא הבא).
אופרטורים לוגיים[]
גימום, איווי, ושלילה[]
ביטוי בוליאני יכול להיות מורכב גם מאוסף של ביטויים בוליאניים פשוטים יותר, המחוברים על ידי קשרים לוגיים, למשל: "אם x שווה 5 או x שווה 6", או: "אם x גדול מ-y וגם y גדול מ-z", וכדומה.
גימום (conjunction בלעז), כלומר הקשר הלוגי "וגם", מיוצג על ידי שני התווים &&:
<condition_1> && <condition_2>כאשר condition_1 וcondition_2 הם שני תנאים בוליאניים, והגימום הוא אמת אם ורק אם שניהם אמת. לדוגמה:
x == 5 && y == 6הוא התנאי שערכו של x הוא 5 וכן ערכו של y הוא 6.
איווי (disjunction בלעז), כלומר הקשר הלוגי "או", מיוצג על ידי שני התווים ||:
<condition_1> || <condition_2>כאשר condition_1 וcondition_2 הם שני תנאים בוליאניים, והאיווי הוא אמת אם ורק אם לפחות אחד מהם אמת אמת. לדוגמה:
x == 5 || y == 6הוא התנאי שערכו של x הוא 5 או שערכו של y הוא 6.
שלילה (negation בלעז), כלומר הקשר הלוגי "לא", מיוצג על ידי התו !:
!<condition>כאשר condition הוא תנאי בוליאני, והשלילה היא אמת אם ורק אם התנאי הוא שקר. לדוגמה:
!(x == 5)הוא התנאי השולל שערכו של x הוא 5.
ניתן גם ליצור תנאים המורכבים ממספר גדול יותר של ביטויים וקשרים לוגיים, ולהשתמש בסוגריים ע"מ לקבוע את סדר חישובם. למשל:
a > b || (a <= b && b==5)תוכל לראות כיצד משתמשים באופרטורים בוליאניים בהתנאי if (ייתכן שתרצה לבדוק זאת בקצרה לפני המעבר לנושא הבא).
הערכת ביטויים לוגיים מורכבים[]
|
|
שקול לדלג על נושא זה נושא זה מסביר את אחת הטכניקות הקצרניות של שפת C (הידועה בקצרנותה). הקוד הנוצר משימוש בטכניקה זו עלול לבלבל מתכנתים מתחילים. עם זאת, טכניקה זו נמצאת בשימוש רב, בעיקר במערכים, ולכן מומלץ שתשוב לנושא כאן כשתגיע לשם. |
בעת הרצת התוכנית מתבצע חישוב של תנאי מורכב משמאל לימין, ובשימוש בקצר לוגי (שיוסבר להלן).
נתבונן בתנאי המורכב:
x == 5 || y == 6מבין שני הביטויים כאן, הביטוי השמאלי, x == 5 הוא זה שיוערך ראשון. כעת יש שתי אפשרויות:
- אם ביטוי זה הוא שקר, עדיין יכול הביטוי המורכב, x == 5 || y == 6, להיות אמת - יש לבדוק אם הביטוי הימני, y == 6, הוא אמת.
- אם ביטוי זה הוא אמת, אז הביטוי המורכב, x == 5 || y == 6, בהכרח אמת. אין צורך אפילו לבדוק את הביטוי הימני. השפה מבטיחה במקרה זה לערוך קצר לוגי - היא כלל לא תעריך את y == 6.
השפה מבטיחה שני סוגי קצרים לוגיים. בתנאי המורכב
<left_condition> || <right_condition>לא יוערך הביטוי right_condition אם left_condition אמת. בתנאי המורכב
<left_condition> && <right_condition>לא יוערך הביטוי right_condition אם left_condition שקר.
בשפת C, הידועה בקצרנותה, מתכנתים משתמשים בקצרים לוגיים באופן תדיר. לדוגמה:
if(x != 0 && 1 / x < 2)
printf("OK");מבטיחה, על ידי קצר לוגי, שלא תתבצע בטעות חלוקה ב0.
תנאי בקרה[]
תנאי בקרה (selection statements) מאפשרים לציין אלה קטעי קוד יבוצעו בהתאם לתנאים כלשהם.
if[]
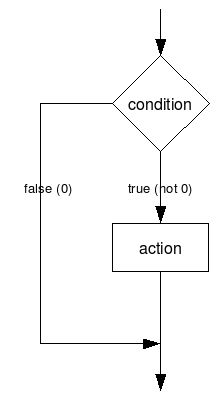
משפטי תנאי מתחילים במילה if, לאחריו ביטוי בוליאני, ולאחריו הפקודה (או הבלוק) שיש לבצע במקרה שהביטוי הבוליאני אמת:
if(<condition>)
<action>כאשר condition הוא התנאי הבוליאני לבדיקה, וaction הוא הפקודה (או הבלוק).
התרשים הבא מראה את התנאי בצורה גרפית:
לדוגמה, קטע הקוד:
if(x == 6)
printf("x is 6");ידפיס אם ערך x אכן 6 תתבצע ההדפסה (ואם לא - לא).
כמובן שנוכל ליצור תנאים מסובכים מעט יותר:
- אפשר להשתמש באופרטורים בוליאניים ולוגיים כדי ליצור תנאים בוליאניים מורכבים לבדיקת הif
- אפשר להשתמש בבלוקים כדי לבצע רצף של פקודות במקרה שהתנאי אמת
|
|
עכשיו תורך: כתוב קטע שיבדוק האם ערך משתנה x הוא 5 או 6, ומדפיס הודעה אם אכן הדבר כן. |
if(x == 5 || x == 6)
printf("x is either 5 or 6");
|
|
עכשיו תורך: כתוב קטע שיבדוק האם ערך משתנה x הוא 5, ואם כן, ישים את הערך 1 למשתנה i, ו2 למשתנה j. |
הפתרון
if(x == 5)
{
i = 1;
j = 2;
}
else[]
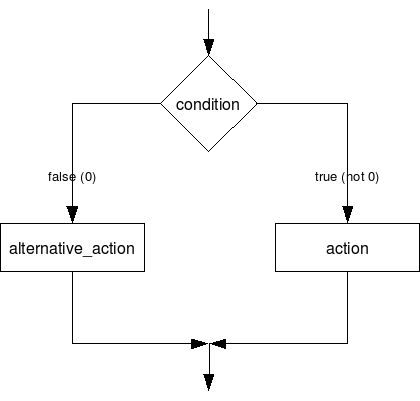
לפעמים צריך לציין הן מה לעשות כשתנאי מתקיים, והן מה לעשות כשאינו מתקיים. במקרה זה אפשר להשתמש בתנאי if / else.
if(<condition>)
<action>
else
<alternative_action>כאן condition הוא תנאי, action הוא פקודה (או בלוק) לביצוע אם התנאי מתקיים, וalternative_action הוא פקודה (או בלוק) לביצוע אם אינו מתקיים.
התרשים הבא מראה את התנאי בצורה גרפית:
לדוגמה:
if(x==6)
y += 2;
else
y = 8;יחבר 2 לy אם x == 6, ויקבע את ערכו של y ל8 אם ערכו של x אינו 6.
else if[]
לפעמים צריך לציין הן מה לעשות כשתנאי מתקיים, והן מה לעשות כשאינו מתקיים, אך תנאי אחר כן מתקיים. במקרה זה אפשר להשתמש בתנאי if / else if.
if(<condition>)
<action>
else if(<alternative_condition>)
<alternative_action>כאן condition הוא תנאי, action הוא פקודה (או בלוק) לביצוע אם התנאי מתקיים, alternative_condition הוא תנאי לבדיקה אם condition הוא שקר, וalternative_action הוא פקודה (או בלוק) לביצוע אם condition הוא שקר אך alternative_condition הוא אמת.
לדוגמה:
if(x==6)
y += 2;
else if(x % 2 == 0)
y = 8;יחבר 2 לy אם x == 6, ויקבע את ערכו של y ל8 אם ערכו של x אינו 6 אך x זוגי.
שילובי if / else if / else[]
ניתן לשלב בין שלושת תנאי הבקרה שראינו. המבנה הכללי ביותר הוא:
- תנאי if, שלאחריו
- אפס או יותר תנאי if else, שלאחר האחרון שבהם (אם יש כאלה)
- תנאי else
אופרטור התניה[]
אופרטור התניה מאפשר לציין ערך שתלוי בתנאי כלשהו. אופן כתיבתו הוא בצורה:
<condition>? <true_value> : <false_value>כאשר condition הוא ביטוי בוליאני, true_value הוא הערך אם condition תקף, וfalse_value הוא הערך אחרת. לדוגמה
a == 3? 1 : 2הוא בעל הערך 1 אם a אכן שווה ל3, והוא בעל הערך 2 אחרת.
חשוב להבין שאפשר להשתמש באופרטור התניה כערך לכל דבר. לדוגמה, ניתן לכתוב:
int b = a == 3? 1 : 2;וכן
prinf("%s is the winner", a > 5? "moshe" : "yaakov");switch-case[]
switch-case הוא סוג נוסף של משפט בקרה. המבנה שלו הוא מהצורה:
switch(<expression>)
{
case <value_0>:
<action_0>
break;
case <value_1>:
<action_1>
break;
...
[default:
<action_default>]
<default_action>
}כאשר:
- expression הוא ערך (לרוב נתון כערכו של משתנה)
- value_0, value_1, ..., הם ערכים קבועים.
- action_0, action_1, ..., הם פקודות או רצפי פקודות.
- default_action הוא פקודה או רצף פקודה.
כאשר רצף התכנית מגיע לפקודת switch, מתבצעים השלבים הבאים:
- הערך expression מחושב
- נבדק מי הוא הערך הראשון מבין הערכים value_0, value_1,... שערכו זהה לexpression. הפקודה המתאימה לערך הראשון הנ"ל תבוצע.
- אם אף ערך מתאים לexpression, ותנאי ברירת המחדל (default) נמצא, אז הפקודה המתאימה לו תבוצע.
התכנית הבאה מדגימה את השימוש בswitch:
#include <stdio.h>
int main()
{
char rep;
printf("Click a number between 1 and 4");
rep = getchar();
switch(rep)
{
case '1':
printf("You clicked 1, have a good day");
break;
case '2':
printf("You clicked 2, have a nice day");
break;
case '3':
printf("You clicked 3, have a happy day");
break;
case '4':
printf("You clicked 4, have a great day");
break;
default:
printf("You did not click a number between 1 and 4");
return -1;
}
return 0;
}נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
לולאות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C לולאות משמשות לחזרה על קטע קוד מספר פעמים. לולאה חוסכת בזמן כתיבת התוכנה ומסדרת את הקוד.
הצורך בלולאות[]
בפעולות חשבוניות, ראינו דוגמה להמרה בין סוגי מעלות שונים כיצד להמיר ממעלות בCelsius למעלות בFahrenheit. נניח שאנו רוצים להדפיס את התרגום למעלות Fahrenheit של מעלות הCelsius בערכים 0, 2, 4, ..., 20. ננסה לעשות זאת כך:
c = 0;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 2;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 4;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 6;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 8;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 10;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 12;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 14;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 16;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 18;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
c = 20;
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);קל לראות שמשהו בעייתי בקוד, והבעייתיות היתה גוברת לו היינו פועלים בתחום גדול יותר, לדוגמה 0, 2, 4, ..., 100. בין היתר:
- הקוד ארוך ומסורבל מאד.
- תמיד ייתכן שהקוד כולל שגיאה כלשהי: ייתכן שטעינו בהעתקת הנוסחה הממירה, לדוגמה. כאן נצטרך לתקן את הקוד ב11 מקומות.
בפרק זה נלמד להשתמש בלולאות, המאפשרות לתרגם את הקוד הקודם לקוד תמציתי יותר:
for(c = 0; c <= 20; c += 2)
{
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}שתוצאתו דומה.
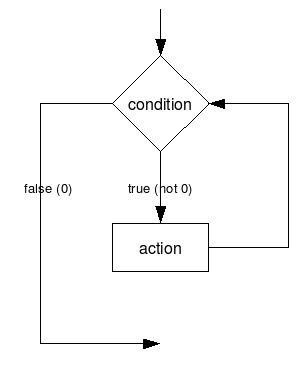
לולאת while[]
לולאת while היא לולאה הפועלת כל עוד תנאי מוגדר מתקיים. אופן כתיבת הלולאה הוא:
while(<condition>)
<action>כאשר condition הוא תנאי בוליאני, וaction הוא ביטוי (או בלוק) המתבצע כל עוד התנאי הבוליאני מתקיים.
התרשים הבא מראה את הלולאה בצורה גרפית:
לדוגמה, קטע הקוד הבא מדפיס את המספרים 1-20 (כל אחד בשורה):
#include<stdio.h>
int main()
{
int i = 1;
while(i <= 20)
{
printf("%d\n",i);
i++;
}
return 0;
}
|
|
עכשיו תורך: כתבו תוכנית שמדפיסה את כל המספרים האי-זוגיים מ-1 עד 20, השתמשו בלולאת while. |
פתרון
#include<stdio.h>
int main()
{
int i = 1;
while(i <= 20)
{
printf("%d\n", i);
i += 2;
}
return 0;
}
לולאת do while[]
לולאה do-while דומה מאוד לקודמתה בהבדל קטן, שבו בכל פעם קודם מבוצע הביטוי, ורק לאחריו נבדק התנאי הבוליאני. אופן הכתיבה הוא:
do
<action>
while(<condition>);
התרשים הבא מראה את הלולאה בצורה גרפית:
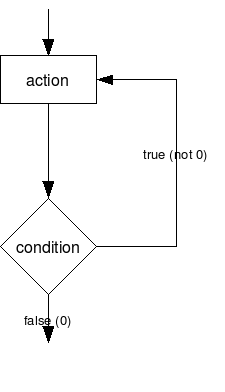
נשים לב שהביטוי יבוצע לפחות פעם אחת, גם אם התנאי אינו מתקיים.
לדוגמה, קטע הקוד הבא מדפיס את המספרים 1-20 (כל אחד בשורה):
#include<stdio.h>
int main()
{
int i=1;
do
{
printf("%d\n",i);
i++;
}
while(i < 20)
return 0;
}
|
|
עכשיו תורך: כתבו תוכנית שמדפיסה את כל המספרים האי-זוגיים מ-1 עד 20, השתמשו בלולאת do-while. |
פתרון
#include<stdio.h>
int main()
{
int i=1;
do
{
printf("%d ",i);
i += 2;
}
while(i < 20);
return 0;
}
לולאת for[]
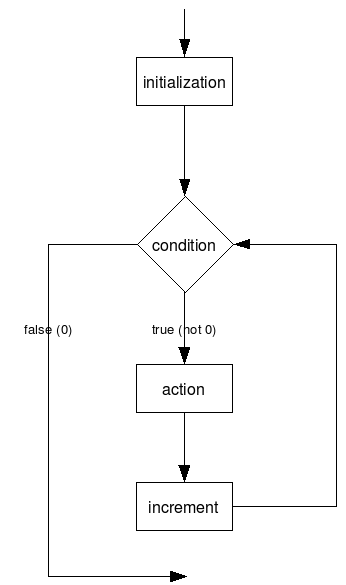
לולאת for תמציתית וגמישה יותר משתי האחרות, אך בעלת תחביר מסובך קצת יותר. אופן כתיבת הלולאה:
for(<initialization>; <condition>; <increment>)
<action>כאשר:
- initialization הוא פקודת (או פקודות) אתחול שיבוצעו פעם אחת בתחילת הלולאה.
- condition הוא תנאי שייבדק כל פעם לפני ביצוע action
- action הוא פקודה (או בלוק)
- increment הוא פקודה (או פקודות) שיבוצעו כל פעם לאחר ביצוע action
התרשים הבא מראה את הלולאה בצורה גרפית:
לדוגמה:
for(i = 0; i < 3; i++)
printf("%d\n", i);תדפיס למסך:
0
1
2
|
|
עכשיו תורך: כתבו תוכנית שמדפיסה את כל המספרים האי-זוגיים מ-1 עד 20, השתמשו בלולאת for. |
פתרון
#include<stdio.h>
int main()
{
int i;
for(i = 1; i <= 20; i += 2)
printf("%d\n",i);
return 0;
}
סכנות בתנאי העצירה[]
כשכותבים לולאות, יש לוודא שתנאי העצירה אכן יתקיים בהכרח בוודאות - המהדר לא יעשה זאת בשבילנו. נתבונן, לדוגמה, בקטע הקוד הבא:
for(i = 1; i <= 20 || i > 20; i++)
printf("Hello\n");לולאה זו לא תעצר לעולם, שכן התנאי להמשך הלולאה תמיד יתקיים. כאשר קטע קוד זה יופעל, התוכנית תראה כאילו ש"קפאה".
דוגמה לשילוב פלט/קלט, תנאים, ולולאות[]
נסיים בתוכנית קטנה המדגימה את השימוש בתנאים ולולאות. התוכנית קולטת מהמשתמש שני מספרים, ומדפיסה הודעה האומרת מה היחס ביניהם. אחר כך היא שואלת את המשתמש אם הוא רוצה להמשיך ולתת שני מספרים נוספים, וכך הלאה, עד שהמשתמש בוחר להפסיק.
#include <stdio.h>
int main()
{
int c;
do
{
int a, b;
printf("Please enter two numbers with a space between them:\n");
scanf("%d %d", &a, &b);
if( a > b)
printf("%d is bigger than %d.\n", a, b);
else if ( a < b )
printf("%d is bigger than %d.\n", b, a);
else
printf("The numbers are equal.\n");
printf("Please enter 1 to repeat, any other number to quit.\n");
scanf("%d", &c);
}
while(c == 1);
return 0;
}להלן הסבר לתוכנית.
נתבונן ראשית במבנה של הקוד בתוך main. הקוד הוא למעשה כמעט כולו לולאת do-while:
int c;
do
{
...
}
while(c == 1);כלומר, עושים פעולה כלשהי כל עוד ערך c הוא 1. מתי נקבע ערכו של c? בתוך הלולאה, נוכל לראות את צמד השורות הבאות:
printf("Please enter 1 to repeat, any other number to quit.\n");
scanf("%d", &c);השורות מבקשות מהמשתמש להכניס ערך (הקובע האם להמשיך בתוכנית), וקולטות את הערך למשתנה c.
חוץ מכך, הלולאה מתחילה בשורות:
int a, b;
printf("Please enter two numbers with a space between them:\n");
scanf("%d %d", &a, &b);המבקשות מהמשתמש להכניס שני ערכים. לאחר שהוכנסו שני הערכים, השורות הבאות מדפיסות את היחס ביניהם:
if( a > b)
printf("%d is bigger than %d.\n", a, b);
else if ( a < b )
printf("%d is bigger than %d.\n", b, a);
else
printf("The numbers are equal.\n");נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
פונקציות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C פונקציה היא אוסף של פקודות המיועדות כולן למטרה פרטנית ומוגדרת היטב. פונקציה יכולה לקבל מידע מהתוכנית בצורת משתנים, ולהחזיר מידע לתוכנית.
הצורך בפונקציות[]
נניח שאנו כותבים תוכנית קטנה להמרת מעלות מCelsius לFahrenheit (ראה גם כאן וכאן). התכנית תתחיל בכך שתדפיס את התרגום למעלות Fahrenheit של מעלות הCelsius בערכים 0, 4, 8, ..., 40, ולאחר מכן תבקש מהמשתמש מעלה בבCelsius, ותדפיס את ערכו בFahrenhei. נרשום את התוכנית כך:
#include <stdio.h>
int main()
{
int c, f;
for(c = 0; c <= 40; c += 4)
{
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
f = 1.8 * c + 32;
printf("This is %d in Fahrenheit\n", f);
return 0;
}נוכל לשים לב שהשורה
f = 1.8 * c + 32;מופיעה פעמיים בתוכנית. זהו דבר בעייתי:
- בכל פעם שנגיע לשורה, נצטרך להיזכר מחדש מה משמעות הביטוי החשבוני.
- אם יתברר לנו ששגינו (לדוגמה, העתקנו מספר בצורה לא נכונה את נוסחת ההמרה), נצטרך למצוא את כל המקומות בהם טעינו, ולתקן כל אחד מהם.
ככל שהתוכנית ארוכה ומסובכת יותר, הבעייתיות בדברים כאלה גדלה.
בפרק זה נלמד לפרק תוכניות לפונקציות, שכל אחת מהן מבצעת פעולה אחת מוגדרת. כך, לדוגמה, נגדיר פונקציה הממירה מעלות כך:
float celsius_to_fahrenheit(float celsius)
{
return 1.8 * celsius + 32;
}הגדרת פונקציה[]
על מנת להגדיר פונקציה, יש לכתוב:
<return_type> <function_name>(<arguments>)
{
<body>
}כאשר:
- return_type הוא סוג הערך המוחזר מהפונקציה (אם לא רוצים שהפונקציה תחזיר אף משתנה, כותבים void כטיפוס המשתנה).
- function_name הוא שם הפונקציה.
- arguments הם ארגומנטים, כלומר משתנים שערכם נקבע מחוץ לפונקציה.
- body הוא הפקודות המתבצעות כשהפונקציה נקראת.
מייד לאחר שם הפונקציה צריכים להופיע סוגריים שבהם תכתב רשימת הפרמטרים שהפונקציה תקבל. גם אם הפונקציה לא מקבלת פרמטרים עדיין יש לכתוב את הסוגריים. לאחר הסוגריים ייפתחו סוגריים מסולסלים שמציינים את תחילת קטע הקוד של הפונקציה, ובסוף הפונקציה יופיעו סוגריים מסולסלים נוספים שסוגרים אותה.
בגוף הפונקציה אפשר לכתוב כל רצף פקודות שכבר ראינו. אם הפונקציה מחזירה ערך, צריך לכתוב בגוף הפונקציה:
return <value>;כאשר value הוא הערך. אם הפונקציה אינה מחזירה ערך, אז אפשר לכתוב בכל קטע
return;דבר שיגרום ליציאה מהפונקציה.
דוגמאות[]
פונקציה עם ערך מוחזר[]
הנה הפונקציה הממירה מספר נקודה-צפה המתאר טמפרטורה בCelsius לטמפרטורה בFahrenheit:
float celsius_to_fahrenheit(float celsius)
{
return 1.8 * celsius + 32;
}הפונקציה מקבלת משתנה מסוג מספר נקודה-צפה ששמו celsius, ומחזירה מספר נקודה-צפה.
פונקציה בלי ערך מוחזר[]
הנה פונקציה המדפיסה את התרגום למעלות Fahrenheit של מעלות הCelsius בערכים 0, 4, 8, ..., 40:
void print_conversion_table()
{
int c, f;
for(c = 0; c <= 40; c += 4)
{
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}
}פונקציה זו איננה מקבלת אף פרמטר, ו(בלי שום קשר) גם אינה מחזירה אף ערך. אפשר לראות שאינה מחזירה אף ערך ע"י כך שהיא מוגדרת כמחזירה void, שהוא טיפוס מיוחד שמשמעו שאין ערך מוחזר.
|
|
כדאי לדעת: בשפת C משמשת המילה השמורה void גם במשמעות שונה לחלוטין, שאותה נראה במצביעים לvoid. אין להתבלבל בין שתי משמעויות נפרדות אלה - הן שונות זו מזו. |
פונקציה בלי ערך מוחזר ופקודת יציאה מפורשת[]
נניח שהחלטנו לשאול את המשתמש האם להדפיס את טבלת ההמרות, ואם המשתמש יקליד את התו 'n', לא נדפיס כלום.. נוכל לכתוב זאת כך:
void print_conversion_table_if_needed()
{
int c, f;
char reply;
printf("Print out conversion table?");
scanf("%c", &reply);
if(reply == 'n')
return;
for(c = 0; c <= 40; c += 4)
{
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}
}בפונקציה הקודמת, נשים לב לשורות:
if(reply == 'n')
return;הפקודה return גורמת ליציאה מהפונקציה (בלי ערך מוחזר בפונקציה זו). אם הפקודה מתבצעת, אז שאר הפקודות עד סוף הפונקציה אינן מתבצעות.
קריאה לפונקציה[]
קריאה לפונקציה נכתבת כך:
<function_name>(<values>)כאשר function_name היא שם הפונקציה, וvalues הם הערכים שיש להשים למשתניה. אם הפונקציה אינה מקבלת ארגומנטים, פשוט רושמים כך:
<function_name>().
להלן דוגמה לקריאה לפונקציה celsius_to_fahrenheit:
#include <stdio.h>
float celsius_to_fahrenheit(float celsius)
{
return 1.8 * celsius + 32;
}
int main()
{
int f;
f = celsius_to_fahreneit(3);
printf("%d", f);
return 0;
}השורה
f = celsius_to_fahreneit(3);קוראת לפונקציה עם הערך 3. כעת הפונקציה מתחילה לפעול, ובתוך הפוקנציה, המשתנה celsius הוא בעל הערך 3. כשהפונקציה מגיעה לשורה
return 1.8 * celsius + 32;חוזר רצף התוכנית לשורה שקראה לה. במקרה זה, הערך המוחזר מהפונקציה יושם למשתנה f.
אם נחזור שוב לתוכנית המקורית שרשמנו בתחילת הפרק, נוכל לכתוב אותה כך:
#include <stdio.h>
float celsius_to_fahrenheit(float celsius)
{
return 1.8 * celsius + 32;
}
int main()
{
int c, f;
for(c = 0; c <= 40; c += 4)
{
f = celsius_to_fahrenheit(c);
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
f = celsius_to_fahrenheit(c);
printf("This is %d in Fahrenheit\n", f);
return 0;
}למעשה, כפי שכתובה התוכנית כעת, נוכל אפילו לוותר על חלק מהמשתנים, ולכתוב אותה בצורה קצרה יותר כך:
#include <stdio.h>
float celsius_to_fahrenheit(float celsius)
{
return 1.8 * celsius + 32;
}
int main()
{
int c, f;
for(c = 0; c <= 40; c += 4)
printf("%d in Celsius is %d in Fahrenheit\n", c, celsius_to_fahrenheit(c));
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
printf("This is %d in Fahrenheit\n", celsius_to_fahrenheit(c));
return 0;
}פונקציות שכבר ראינו[]
אם כי זה הפרק הראשון העוסק בפונקציות, כבר נתקלנו בפונקציות בפרקים קודמים. הבה ניזכר בהן.
הפוקנציה main[]
כל תוכנית בשפת C חייבת לכלול את הפונקציה main. זוהי הפונקציה הראשונה שמורצת כאשר מורצת התוכנית, וכאשר מסתיימת הרצתה, מסתיימת הרצת התוכנית.
אנו ראינו אותה בגרסה הזו:
int main()
{
<body>
}(לפונקציה גם גירסאות בהן היא מקבלת ארגומנטים, אך לא נדון בכך כעת.) אפשר לראות שהפונקציה מחזירה מספר שלם. לפי חוקי השפה, יש להחזיר את הערך 0 אם הכל התנהל כשורה, וערך שאינו 0 אם משהו השתבש.
|
|
שימו לב: לעתים אפשר לראות את הפונקציה main מוגדרת כך:void main()
כלומר, בגרסה שאינה מחזירה ערך. מדובר בשגיאה. |
|
|
כדאי לדעת: אין מוסכמה חד משמעית לגבי השאלה מהו "שיבוש" שחל בזמן ריצת התוכנית. עם זאת, להלן מספר אפשרויות סבירות:
|
פונקציות פלט וקלט[]
בפלט וקלט ראינו כבר את הפונקציות printf, scanf, putchar, ו getchar.
הצהרה על פונקציות[]
נתבונן בתוכנית הבאה:
#include <stdio.h>
int main()
{
int a, b;
printf("Enter two numbers:\n");
scanf("%d %d", &a, &b);
print_bigger( a, b );
return 0;
}
void print_bigger(int x, int y)
{
if (x>y)
printf("%d",x);
else
printf("%d",y);
}לכאורה, הכל בסדר בתוכנית. ראשית מתחילה לפעול (כתמיד) הפונקציה main. כאשר מגיעים לשורה
print_bigger( a, b );תיקרא הפונקציה print_bigger, ולאחר שתסתיים הקריאה לפונקציה, תחזור התוכנית לmain.
על אף שהכל נראה בסדר, המהדר יודיע שבתוכנית יש שגיאה. כאשר המהדר מגיע לשורה הקוראת לprint_bigger, הוא עדיין לא יודע שיש פונקציה כזאת - היא מוגדרת מאוחר יותר בקובץ. המהדר יתלונן שאין פונקציה כזו. לדוגמה, המהדר gcc מתלונן כך:
main.c: In function ‘main’:
main.c:11: warning: implicit declaration of function ‘print_bigger’כמובן שנוכל לפתור את הבעיה על ידי החלפת סדר הפונקציות, אך לא תמיד הדבר אפשרי: נראה כך בהמשך בפונקציות רקורסיביות ומודולים.
פתרון מקובל אחר, הוא להשאיר את הסדר כפי שהוא, אך להצהיר על הפונקציה print_bigger לפני הפונקציה main, כך שהמהדר ידע על קיומה ועל האופן שבו היא צריכה להקרא. הצהרה כזאת (declaration בלעז) מתבצעת על ידי כתיבת האב-טיפוס (prototype בלעז) של הפונקציה, כלומר: הטיפוס המוחזר, שם הפונקציה וטיפוסי הפרמטרים, עם נקודה-פסיק בסוף. במקרה שלנו, לדוגמה, ההצהרה תראה כך:
void print_bigger(int x, int y);כעת, אם ההצהרה מופיעה לפני הקריאה לפונקציה, נוכל לכתוב את הגדרת הפונקציה (definition בלעז) אפילו אחרי הקריאה לפונקציה, והתוכנית עדיין תעבור הידור ותרוץ כנדרש:
#include <stdio.h>
/* This is a declaration. */
void print_bigger(int x, int y);
int main()
{
int a, b;
printf("Enter two numbers:\n");
scanf("%d %d", &a, &b);
print_bigger( a, b );
return 0;
}
/* And here is the definition. */
void print_bigger(int x, int y)
{
if (x>y)
printf("%d",x);
else
printf("%d",y);
}פונקציות רקורסיביות[]
|
|
שקול לדלג על נושא זה מומלץ לשקול לדלג על נושא זה בפעם הראשונה בה נתקלים בו, ולחזור אליו רק לאחר מעבר כללי על כל הספר. |
פונקציה היא רקורסיבית אם היא קוראת לעצמה. לשפת C אין כללים מיוחדים לפונקציות רקורסיביות - הגדרותיהן, והקריאות להן ומהן, דומות לאלו של פונקציות לא רקורסיביות.
לדוגמה, להלן פונקציה לא רקורסיבית לחישוב עצרת:
unsigned long factorial(unsigned int n)
{
unsigned long fact = 1;
unsigned int i;
for(i = 1; i <= n; ++i)
fact *= i;
return fact;
}ולהלן פונקציה רקורסיבית לחישוב עצרת:
unsigned long factorial(unsigned int n)
{
if(n == 0)
return 1;
return n * factorial(n - 1);
}או בצורה קצרה יותר:
unsigned long factorial(unsigned int n)
{
return n == 0? 1 : n * factorial(n - 1);
}מעט על פונקציות והנדסת תוכנה[]
שפת C משמשת לכתיבת תוכנות מסובכות מאד. הקוד של ליבת לינוקס, לדוגמה, מורכב ממיליוני שורות קוד. בשפת C מתמודדים עם מורכבות זו בעזרת חלוקת הקוד לפונקציות (וכן, במידה מסויימת, על ידי חלוקה למודולים). תכנות טוב מבוסס על חלוקת כל תוכנית למספר פונקציות, כך שלכל אחת מטרה מוגדרת אחת. כאשר פונקציה עושה יותר מדי פעולות, או כאשר קטעי קוד חוזרים על עצמם בפונקציות שונות, מחלקים את הקוד לפונקציות קטנות יותר. בצורה זו ניתן לפשט תוכנית שמבצעת משימות מורכבות לתוכנית שבה כל פונקציה לבדה מבצעת משימה פשוטה, ומורכבות התוכנית נובעת מהבנייה ההדרגתית של פונקציות אחת על השנייה. הייתרונות המושגים על ידי כך:
- הקוד נוח לקריאה וברור.
- קל יותר לשנות או לתקן כל פונקציה בנפרד, כך שאם מתגלה בעיה באחד מחלקי התוכנית מספיק לתקן רק את החלק הזה, מבלי שהדבר ישפיע על שאר חלקי התוכנית.
- הקוד מאפשר שימוש חוזר. אם קטע קוד נבדק ועובד, ואנו צריכים את אותו קטע קוד בחלק אחר של התוכנית, אין צורך לשכפל אותו.
נשתמש בקוד שראינו בצורך בפונקציות כדוגמה (למרות שזהו קוד פשוט מאד). ראשית נתבונן בפונקציה main:
#include <stdio.h>
int main()
{
int c, f;
for(c = 0; c <= 40; c += 4)
{
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
f = 1.8 * c + 32;
printf("This is %d in Fahrenheit\n", f);
return 0;
}ברור למדי שהפונקציה מבצעת שני דברים: מדפיסה טבלת המרות, וממירה שאילתה בודדת. נחלק, לכן, את הקוד לפונקציות:
#include <stdio.h>
void print_init_conversion_table();
void handle_conversion_query();
int main()
{
print_init_conversion_table();
handle_conversion_query();
return 0;
}
void print_init_conversion_table()
{
int c, f;
for(c = 0; c <= 40; c += 4)
{
f = 1.8 * c + 32;
printf("%d in Celsius is %d in Fahrenheit\n", c, f);
}
}
void handle_conversion_query()
{
int c, f;
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
f = 1.8 * c + 32;
printf("This is %d in Fahrenheit\n", f);
}כעת נשים לב לשורת ההמרות שחוזרת על עצמה (כפי שראינו מקודם), ונהפוך אותה לפונקציה:
#include <stdio.h>
float celsius_to_fahrenheit(float celsius);
void print_init_conversion_table();
void handle_conversion_query();
int main()
{
print_init_conversion_table();
handle_conversion_query();
return 0;
}
void print_init_conversion_table()
{
int c, f;
for(c = 0; c <= 40; c += 4)
printf("%d in Celsius is %d in Fahrenheit\n", c, celsius_to_fahrenheit(c));
}
void handle_conversion_query()
{
int c;
printf("Enter degrees in Clesius: ");
scanf("%d", &c);
printf("This is %d in Fahrenheit\n", celsius_to_fahrenheit(c));
}
float celsius_to_fahrenheit(int celsius)
{
return 1.8 * celsius + 32;
}איכות הקוד כעת טובה יותר:
- הקוד חסין יותר מטעויות - צמצמנו את מספר המקומות בהם נצטרך לשנות משהו אם יש טעות בנוסחת ההמרה, לדוגמה.
- הקוד גמיש יותר - קל יהיה לשנות את הקוד אם תגיע דרישה לתוכנית שתעשה משהו אחר, לדוגמה:
- תוכנית ששואלת את המשתמש האם להדפיס טבלת המרה או לענות על שאילתה
- תוכנית שמדפיסה טבלת המרה, ואז עונה על שאילתות בלולאה עד שהמשתמש מציין שסיים
במעט על מבנים והנדסת תוכנה נדבר עוד על עניינים אלה בהקשר של מבנים.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מערכים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C מערך הוא מבנה נתונים שמאפשר שמירה של משתנים רבים מאותו טיפוס תחת אותו שם, כאשר כל אחד מהמשתנים מקבל מספר מזהה ייחודי. שימוש במערכים מאפשר עבודה נוחה עם מידע שמורכב מחלקים רבים הזהים זה לזה.
מהו מערך?[]
בהסבר מהם משתנים בפרק משתנים, עמדנו על כך שאפשר לחשוב על משתנה כ"תיבה", שאפשר לשים בה ערכים. באופן דומה, אפשר לחשוב על מערך כעל "שורת תיבות". לשורת התיבות יש שם (באופן דומה לכך שלמשתנה יש שם), ואפשר לגשת לתיבה ספיציפית על ידי ציון מספר התיבה בשורה.
בתרשים הבא, לדוגמה, מוצג המשתנה grade, שהוא כעין תיבה (המורכבת משני בתים), ובתוכה כעת המספר 80. בתרשים גם מוצג המערך grades, מערך באורך ארבע, שהוא כעין שורה של ארבע תיבות (שכל אחת מהן מורכבת משני בתים), ובתיבות כעת המספרים 90, 80, 56, ו100.

הגדרת מערך[]
הגדרת מערך צריכה להיות מהצורה:
<type> <name>[<size>];כאשר type הוא סוג המשתנה של אברי המערך, name הוא השם שאנו בוחרים למערך כולו, וsize (שחייב להיות שלם חיובי) הוא מספר האיברים שמכיל המערך.
לדוגמה, נתבונן בקטע הקוד הבא:
int array1[30];
char array2[50];
double array3[1];- השורה הראשונה מכריזה על מערך שלמים array1 בעל 30 איברים.
- השורה השניה מכריזה על מערך תווים array2 בעל 50 מקומות.
- השורה השלישית מכריזה על מערך מספרי נקודה צפה array3 בעל איבר יחיד.
גישה לאברי מערך[]
כדי לגשת לאיבר במערך, אפשר להשתמש באינדקס: יש לכתוב את שם המערך ואחריו בתוך סוגריים מרובעים את המספר הסידורי של האיבר במערך:
array1[2] = 5;בדוגמא זו, המשתנה שהאינדקס שלו הוא 2 במערך array1 שהוגדר קודם מקבל את הערך 5.
בשפת C נהוג כי האינדקס הראשון במערך הוא 0 ולא 1. כלומר,
array1[0]הוא האיבר הראשון במערך. כתוצאה מכך, האיבר האחרון במערך בגודל n הוא בעל המספר הסידורי n - 1. אם נכתוב
array1[30]נחרוג בכך מגבולות המערך, כי האיבר מס' 29 הוא האיבר האחרון בו.
|
|
שימו לב: חלק גדול משגיאות הריצה של מתחילים בשפת C נובע משיכחה של נקודה זו. |
יתרונות מערכים על פני משתנים רבים[]
נתחיל במספר משימות פשוטות לשימוש במערכים. מיד בהמשך נשתמש בדוגמאות כדי להבין את הייתרונות שבשימוש במערכים.
|
|
עכשיו תורך: כתוב תוכנית שקולטת מהמשתמש 10 מספרים שלמים, ושומרת את המספרים במערך. |
פתרון
אפשר לכתוב זאת כך:
#include <stdio.h>
int main()
{
int numbers[10];
int i;
for(i = 0; i < 10; i++)
{
int temp;
scanf("%d",&temp);
numbers[i] = temp;
}
return 0;
}או, ביתר קיצור, כך:
#include <stdio.h>
int main()
{
int numbers[10];
int i;
for(i = 0; i < 10; i++)
scanf("%d",&numbers[i]);
return 0;
}
|
|
עכשיו תורך: כתוב תוכנית שקולטת מהמשתמש 10 מספרים שלמים, שומרת את המספרים במערך, ומדפיסה אותם בסדר הפוך לסדר קליטתם. |
פתרון
#include <stdio.h>
int main()
{
int numbers[10];
int i;
for(i = 0; i < 10; i++)
scanf("%d",&numbers[i]);
for(i = 9; i >= 0; i--)
printf("%d\n",numbers[i]);
return 0;
}
הדוגמאות הפשוטות שראינו מספיקות כדי להבין את יתרונות המערכים. להלן תוכנית הקולטת 10 ערכים ומדפיסה אותם בסדר הפוך, שאינה משתמשת במערכים:
int main()
{
int num0, num1, num2, num3, num4, num5, num6, num7, num8, num9;
scanf("%d",&num0);
scanf("%d",&num1);
scanf("%d",&num2);
scanf("%d",&num3);
scanf("%d",&num4);
scanf("%d",&num5);
scanf("%d",&num6);
scanf("%d",&num7);
scanf("%d",&num8);
scanf("%d",&num9);
printf("%d\n",num9);
printf("%d\n",num8);
printf("%d\n",num7);
printf("%d\n",num6);
printf("%d\n",num5);
printf("%d\n",num4);
printf("%d\n",num3);
printf("%d\n",num2);
printf("%d\n",num1);
printf("%d\n",num0);
return 0;
}
נוכל לראות יתרונות בולטים לגרסה המשתמשת במערכים:
- במקום להשתמש בעשרה משתנים שונים די להגדיר משתנה יחיד, תחת השם numbers.
- אם התוכנית הייתה צריכה לעבוד עם מספר גדול מספיק של של משתנים, נניח 100, לא היה מעשי להגדיר משתנה לכל אחד מהם.
- לעתים לא יודעים מראש את מספר המשתנים (כמו, לדוגמה, המקרה שבו גם מספר זה מתקבל בקלט). הפועל היוצא הוא שלא היינו יודעים כמה משתנים להגדיר. עם זאת, כשנגיע לניהול זיכרון דינאמי, נראה שאפשר להקצות מערכים בגדלים הנקבעים בזמן הריצה (כמו מקלט, לדוגמה).
- הקוד המשתמש בלולאות קצר יותר. כך לדוגמה, הדפסת האיברים על ידי לולאה (2 שורות), קצרה יותר מהדפסתם בצורה פרטנית (10 שורות).
אתחול מערך[]
לעתים, כאשר מייצרים מערך, יש לתת ערך התחלתי לאיבריו. לדוגמה, נניח שמייצרים מערך של שלמים בגודל 3, ורוצים להכניס לו את האיברים 12, 22, ו33.
כפי שראינו בגישה לאברי מערך, אפשר לגשת לכל אחד מאיברי המערך. נוכל, לכן, להשתמש בהשמה לכל אחד מאיבריו:
int nums[3];
nums[0] = 12;
nums[1] = 22;
nums[2] = 33;עם זאת, לצורך אתחול המערך בלבד, השפה מאפשרת צורה מקוצרת יותר:
int nums[3] = {12, 22, 33};מחרוזות - מערכים של תווים[]
אחד השימושים הנפוצים של מערכים הוא לשמירת מילים או משפטים על ידי מחרוזות, כלומר מערכים של תווים. שפת C כוללת פונקציות עזר רבות למחרוזות. תוכל לקרוא על כך כאן.
זהירות בטיפול במערכים[]
שימוש שגוי במערכים עלול לגרום לתוצאות קשות.
גלישה מגבולות המערך[]
נתבונן בקטע הקוד הבא:
/* An array of 3 places. */
int nums[3];
/* This is an error: the array does not have 10 places. */
num[10] = 12;הקוד ניגש למערך בתא 10, למרות שתא זה כלל אינו חלק מהמערך. זוהי שגיאה, כמובן.
השלכות הגלישה ממערך[]
מה תהיה השפעת קוד זה? הדבר תלוי במערכת בה הקוד רץ, אולם היא יכולה להיות חמורה מאד. ייתכן שבמחשב אחד תופיע בעיה קלה יחסית, אך במחשב אחר (או באותו מחשב בזמן אחר) תופיע בעיה חמורה הרבה יותר.
כדי להבין את חומרת הסכנה הטמונה בשגיאות גלישה, כדאי לדעת שיש קבוצת התקפות עוינות על מחשבים, הידועה בשם buffer overrun, המבוססת בדיוק על חוסר עירנות של מתכנתים בנקודה זו.
מערכים בגודל לא-ידוע מראש[]
|
|
שימו לב: נושא זה מניח שיש לך מהדר חדש יחסית. במהדרים ישנים יותר - המצב שונה. |
ביתרונות מערכים על פני משתנים רבים ראינו תוכנית שקולטת מספרים ומדפיסה אותם בסדר הפוך לסדר קליטתם. התוכנית הניחה שהמשתמש רוצה להפוך בדיוק 10 מספרים. במהדרים חדשים יחסית, קל לשנות את התוכנית כך שמספר המספרים שהמשתמש רוצה להפוך - גם הוא יהיה חלק מהקלט:
#include <stdio.h>
/* Queries the user for how many
numbers she wants reversed. */
int find_how_many_numbers();
int main()
{
int num_numbers = find_how_many_numbers();
int numbers[num_numbers];
int i;
for(i = 0; i < num_numbers; i++)
scanf("%d",&numbers[i]);
for(i = num_numbers - 1; i >= 0; i--)
printf("%d\n",numbers[i]);
return 0;
}
int find_how_many_numbers()
{
int num_numbers;
printf("Please enter how many numbers to reverse: ");
scanf("%d", &num_numbers);
return num_numbers;
}בקוד זה, חשוב לשים לב לשורות הבאות:
int num_numbers = find_how_many_numbers();
int numbers[num_numbers];השורה הראשונה מאתחלת את num_numbers לערך המוחזר מfind_how_many_nubers (שהיא פונקציה שמבקשת מהמשתמש להקליד את מספר המספרים שברצונו להפוך, ומחזירה את המספר שהקליד). השורה השניה מייצרת מערך בגודל מספר זה.
מערכים רב ממדיים[]
ניתן לחשוב על מערך כשורה המכילה מספר תאים, כאשר כל תא הוא תו, שלם, או מספר נקודה צפה. אפשר אפילו להגדיר מערך שבו כל תא הוא מערך. מערך רב מימדי הוא מערך של מערכים.
להלן דוגמה למערך דו-מימדי:
int matrix_2d[10][3];זהו מערך של 10 מערכים, כל אחד בעלי 3 איברים. כדי לגשת לאיבר השני של המערך השלישי, נרשום
/* Access to the second element of the third array. */
matrix_2d[2][1] = 2;גם כאן, כמובן, יש להיזהר מגלישה:
/* Error! out of range */
matrix_2d[2][10] = 2;אין מניעה לעצור בהכרח בשני מימדים. אפשר להגדיר מערך בעל מספר שרירותי של מימדים. להלן דוגמה למערך בעל שישה מימדים:
/* A 6 dimensional array. */
int matrix_6d[5][8][2][9][3][1];
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מחרוזות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C מחרוזת היא רצף של תווים. מחרוזות משמשות על פי רוב בתכנות ליצוג מילים ומשפטים.
מעט לגבי תווים[]
כבר ראינו שתו (char) הוא טיפוס בעל בית יחיד, המשמש לתווי א"ב או ערכים מספריים קטנים. אנו יכולים להחליט שלמספרים כלשהם יש משמעות מיוחדת מבחינתנו, אך את המחשב מעניינים רק הערכים המספריים של תו. במחשב כלשהו, לדוגמה, ערך התו 'a' יכול להיות 97. מבחינת מחשב זה, על כן, אין הבדל בין 'a' לבין 97.
בשפת C יש מוסכמה שעל פיה התו בעל הערך המספרים 0 הוא התו הריק. בפרק זה נראה שיש משמעות מיוחדת לתו הריק.
|
|
שימו לב: התו הריק 0 אינו תו הרווח ' '. |
הגדרת מחרוזת[]
המחרוזת כמערך תווים[]
מחרוזת ב-C מוגדרת על ידי מערך של משתנים מסוג char. לדוגמה:
char my_string[5];היא הכרזה על מערך בשם my_string בעל מקום ל5 תווים.
עם זאת, מחרוזת היא יותר מאשר סתם מערך תווים. שאר הנושא מדבר על כך.
חשיבות התו הריק[]
קיימת מוסכמה שמחרוזת היא יותר מאשר מערך של תווים. המוסכמה אומרת שתווי המחרוזת מתחלקים לשלושה חלקים:
- התווים עד לתו הריק הראשון
- התו הריק הראשון מסמן את סוף התווים "הנחשבים" במחרוזת
- מהתו הראשון ועד סוף המערך, מתעלמים מתווי המחרוזת
(על פי המוסכמה, אם המערך אינו מכיל את התו הריק, אז המחרוזת אינה חוקית).
מיד בהמשך נראה דוגמה לכך.
אורך מחרוזת[]
לפי המוסכמה, התו הריק הראשון מסמן את סוף התווים "הנחשבים" במחרוזת. לכן, אורכה של מחרוזת נחשב מספר התווים מתחילת המערך ועד (לא כולל) התו הריק הראשון במערך.
נשים לב לכן, שלמחרוזת יש שתי תכונות גודל:
- למחרוזת, כמו לכל מערך אחר, יש גודל, והוא קובע את המספר המקסימלי של התווים שהמחרוזת יכולה להחזיק.
- למרוזת יש גם אורך, שהוא מספר התווים עד לתו הריק הראשון, והוא קובע את אורך המחרוזת בפועל עבור תוכנה הנוכחי.
דוגמה[]
להלן מערך של 14 תווים, המורכב מ3 חלקים:
- תחילה מופיע הרצף "Shalom olam".
- לאחר מכן מופיע התו הריק.
- לבסוף, לאחר התו הריק מופיעים עוד תווים, שלפי המוסכמה אינם נחשבים לתוכן המחרוזת.
|
|
עכשיו תורך: מה גודל המערך הנ"ל, ומה אורך המחרוזת? |
פתרון
במערך יש 14 תאים, ולכן גודלו 14. במחרוזת יש 11 תווים עד התו הריק, ולכן אורכה 11.
אתחול מחרוזת[]
היות שמחרוזת היא מערך, ניתן לאתחל אותה כפי שמאתחלים כל מערך, או, לחלופין, אפשר להשים ערכים לאיבריה ממש כמו לכל מערך אחר. בשני המקרים יש לאתחל או להשים גם את התו הריק.
לדוגמה, אם נרצה לאתחל את המחרוזת my_string ל"wiki", אפשר לאתחל אותה כך:
char my_string[5] = {'w', 'i', 'k', 'i', 0};או, לחלופין, אפשר להשים ערכים לאיבריה כך:
my_string[0] = 'w';
my_string[1] = 'i';
my_string[2] = 'k';
my_string[3] = 'i';
my_string[4] = 0;השפה גם מאפשרת צורת אתחול מיוחדת למחרוזות, הקריאה יותר משתי האפשרויות הקודמות:
char my_string[] = "wiki";נשים לב שבשיטה האחרונה אין צורך לציין את גודל המחרוזת (הוא מחושב לבד על ידי המהדר, אם כי זו לא טעות לכתוב אותו), וכן לא כותבים מפורשות את התו 0 (המהדר לוקח אותו בחשבון).
נזכור, לכן, שבקטעי קוד מהצורה:
char my_string_1[10] = {'w', 'i', 'k', 'i', 0};
char my_string_2[] = "wiki";תמיד יש לחשוב מהו גודל המערך ומה אורך המחרוזת.
|
|
עכשיו תורך: מהם גודלי המערכים ואורכי המחרוזות בקטע הקוד? |
פתרון
my_string_1 הוא מערך בגודל 10. לאחר האתחול כאן, הוא מכיל 5 תווים: 4 תווי תוכן, והתו הריק; לכן ארכו 4. my_string_2 הוא מערך בגודל 5: המהדר מחשב שיש צורך ב4 תווי תוכן ובתו ריק, ומקצה גודל מתאים לכך. לאחר האתחול כאן, הוא מכיל 5 תווים: 4 תווי תוכן, והתו הריק; לכן ארכו 4.
פונקציות בסיסיות לטיפול במחרוזות[]
עבודה עם מחרוזות כוללת לרוב את אותן המטלות. ספריות המערכת כוללות פונקציות שימושיות למטלות נפוצות. כדי להשתמש בפונקציות אלו, יש להוסיף לתחילת הקובץ את השורה:
#include <string.h>מציאת אורך מחרוזת[]
הפונקציה strlen מחזירה את אורכה של מחרוזת נתונה. לדוגמה:
char str[15] = "Boker Tov!";
int length = strlen( str );
printf("%d\n", length);ידפיס את המספר 10, שכן ישנם עשרה תווים עד לתו הריק הראשון.
העתקת מחרוזת[]
היות שמחרוזת היא מערך, אי אפשר להעתיק מחרוזת על ידי השמה פשוטה כמו במשתנים רגילים. קטע הקוד הבא, לדוגמה, אינו חוקי:
char source[] = "Shalom";
char dest[] = str1; /* ERROR! */כדי להעתיק מחרוזת, יש להעתיק תו אחר תו. הפונקציה strcpy עושה זאת. לדוגמה:
char source[] = "Shalom";
char dest[15];
strcpy( dest, source );
printf("%s\n%s\n", source, dest);ידפיס
Shalom
Shalomstrcpy מקבלת שתי מחרוזות, ומעתיקה את השנייה לתוך הראשונה, כולל תו סיום המחרוזת.
שרשור מחרוזות[]
הפונקציה strcat משרשרת מחרוזת אחת לסוף של מחרוזת אחרת:
char source[] = "olam";
char dest[30] = "Shalom ";
strcat( dest, source );
printf("%s\n%s\n", source, dest);קוד זה ידפיס:
olam
Shalom olamהאיור הבא מראה את המחרוזות לפני ואחרי פעולת השרשור:
שים לב במיוחד לתווים הריקים.
פלט וקלט[]
פלט[]
הפונקציה printf[]
בפלט וקלט הכרנו את הפונקציה printf המאפשרת להציג ערכי משתנים על המסך. אפשר להשתמש בפונקציה זו לפלט מחרוזות. לציון משתנה מסוג מחרוזת בפקודת קלט/פלט משתמשים ב%s. לדוגמה:
char name[] = "Moshe";
printf("My name is %s\n", name);קוד זה יציג על המסך את הפלט:
My name is Mosheפונקציות אחרות[]
הספריה הסטנדרטית כוללת פונקציות נוספות לפלט מחרוזות, לדוגמה puts.
קלט[]
הפונקציה scanf[]
בפלט וקלט ראינו את הפונקציה scanf המאפשרת לקלוט ערכים למשתנים. אפשר להשתמש בפונקציה זו לקלט מחרוזות. לציון משתנה מסוג מחרוזת בפקודת קלט/פלט משתמשים ב%s. לדוגמה:
char name[10];
printf("Please enter your name:\n");
scanf("%9s", &name);קוד זה יציג על המסך:
Please enter your name:ויחכה לקלט מהמשתמש. עד 9 תווים ייקלטו למשתנה name, או, אם 9 התווים הראשונים כוללים רווח, רק התווים עד הרווח הראשון.
|
|
כדאי לדעת: נשים לב לקובע הרוחב 9 ב"%9s". גם אם המשתמש יקליד יותר תווים, הקלט לא ייגלוש מתחום המחרוזת name. נדבר על כך עוד בהבעייתיות המיוחדת בפונקציות קלט. |
הפונקציה fgets[]
הפונקציה fscanf מאפשרת לקלוט מחרוזות עד הרווח הראשון. לפעמים רוצים לקלוט שורה שלמה, גם אם היא כוללת רווחים. לצורך כך אפשר להשתמש בfgets, כך:
char a[50];
fgets(a, 49, stdin);הקריאה:
fgets(a, 49, stdin);תקלוט עד 49 תווים. אם ב49 התווים הראשונים יש מעבר לשורה חדשה (על ידי Enter), ייקלטו רק התווים עד שם.
|
|
כדאי לדעת: לעת עתה נוכל להתעלם מהארגמונט השלישי של הפונקציה, stdin, נעסוק בו בפלט וקלט קבצים. |
פונקציות אחרות[]
הספריה הסטנדרטית כוללת פונקציות נוספות לקלט מחרוזות, לדוגמה gets. לפני השימוש בהם, מומלץ לקרוא על הבעייתיות המיוחדת בפונקציות קלט.
זהירות בטיפול במחרוזות[]
גישה שגוייה לאיברי המחרוזת כמערך[]
כבר ראינו שבשפת C, אם מערך הוא בגודל 20, אז גישה לאיבר מעבר לכך, נניח 33, גולשת מתחום המערך, ויכולה לגרום לבעיות. חשוב להבין שקל מאד ליפול לבעיות אלו דווקא בעבודה עם מחרוזות. נתבונן, לדוגמה, בקטע הקוד הבא:
char src[] = "Hello, world!";
char dest[4];
strcpy(dest, src);קטע קוד זה מכיל שגיאה, מפני שבמערך dest אין מספיק מקום להעתיק את תווי "Hello, world!".
המסקנה, על כן, היא שבעבודה עם מחרוזות, ובעיקר עם פונקציות המעתיקות דברים למחרוזות (לדוגמה, strcpy, strcat, או פונקציות הקלט שראינו) - יש לנהוג בזהירות רבה.
הבעייתיות המיוחדת בפונקציות קלט[]
עם תשומת לב מספיקה, אפשר להבטיח שמרבית הקריאות המטפלות במחרוזות יעבדו בצורה בטוחה. כך, לדוגמה, לפני כל קריאה לstrcpy, אפשר לבדוק את אורכי המחרוזות, ולבצע את הפעולה רק אם אין סכנת גלישה. ישנה בעייה מיוחדת בקלט, מפני שאין דרך לדעת מראש כמה תווים תקליד המשתמשת. קטע הקוד הבא, לדוגמה, משתמש בscanf ללא קובע רוחב:
char name[10];
printf("Please enter your name:\n");
scanf("%s", &name);חשוב להבין שזהו קטע קוד בעייתי ביותר. בכלל, כשעוסקים בקלט מחרוזות (אולי על ידי שימוש בפונקציות ספריה אחרות), חשוב לשים לב לנקודה.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מצביעים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C מצביע הוא סוג מיוחד של משתנה שערכו כתובתו של משתנה או קבוע אחר. מצביעים מהווים אלמנט חשוב ומרכזי בתכנות בשפת C - הם מוסיפים מימד חדש של גמישות בניהול משתנים ופונקציות.
|
|
שימו לב: מצביעים עלולים להיות מסובכים להבנה בתחילה. מומלץ לקרוא פרק זה בעיון רב. |
הצורך במצביעים[]
נניח שיש שני משתני מספרים שלמים, a וb, המכילים ערכים כלשהם, ורוצים להחליף בין ערכיהם. כבר ראינו כיצד לעשות כך בהחלפה בין ערכי שני משתנים. כעת אנו שמים לב שפעולה זו חוזרת על עצמה מספר פעמים, ולכן אנו מחליטים לכתוב פונקציה המחליפה בין ערכי שני משתנים (ראה גם מעט על פונקציות והנדסת תוכנה).
להלן ניסיון שגוי לכתוב פונקציה כזו:
/* Useless attempt for a function that swaps variables' values. */
void swap(int x, int y)
{
int temp = x;
x = y;
y = temp;
}מעט מחשבה תראה לנו שהפוקנציה לא תעזור לנו במטרתנו. להלן קטע קוד שקורא לפוקנציה:
char a = 'a', b = 'b';
swap(a, b);
printf("%c %c\n", a, b);אם נריץ קוד זה, נראה פלט
a bכלומר, ערכי המשתנים לא הוחלפו. הסיבה לכך שנכשלנו היא שהשתמשנו ב-call by value, כלומר - הערכים אותם קיבלה הפונקציה הם רק העתקים של הערכים המקוריים. השינויים שהפונקציה עושה מתבצעים רק על ההעתקים האלה, ולכן לא משפיעים על המקור. נחזור לנקודה זו כשנדבר על מבנה הזיכרון ומשתנים, ובשימוש במצביעים להעברת משתנים לפונקציה נראה כיצד מצביעים מאפשרים להעביר נתונים לפונקציות בצורה גמישה יותר.
מבנה הזיכרון ומשתנים[]
מודל פשוט לזיכרון[]
כדי להבין מצביעים, ראשית יש להבין את זיכרון המחשב (RAM), או ביתר דיוק, הפשטה שלו. אפשר לחשוב על זיכרון המחשב כמערך בעל מספר תאים גדול - כל תא בגודל תו. כאשר אנו מגדירים משתנה, מוקצים לו בזכרון תא אחד או יותר, לפי סוג המשתנה.
נתבונן, לדוגמה, בקטע הקוד הבא:
char c = 'a';
int d;התרשים הבא מראה מצב אפשרי של קטע מהזיכרון.

התרשים מראה חלק מה"מערך" שהוא זיכרון המחשב (כלומר, אפשר לחשוב שהמערך גם נמשך שמאלה וימינה, אלא שרק קטע זה מצוייר כאן). שני המשתנים מיוצגים כאן בקטעי תאים אפורים בהירים:
- המשתנה c הוא מסוג תו, ותופס תא אחד. תא זה הוא (במקרה) תא מספר 2000. נהוג לומר שהוא בכתובת 2000. המשתנה מכיל את התו 'a'.
- המשתנה d הוא מסוג מספר שלם, ותופס 4 תאים (בדוגמה זו; במחשב אחר, המשתנה יכל לתפוס 8 תאים, לדוגמה). הוא מופיע 4 תווים לאחר c, ולכן כתובתו 2004. המשתנה טרם אותחל, ולכן ערכו הוא מה שהזיכרון הכיל במקרה ב4 תאיו (במקרה זה, 1334, לדוגמה).
כאשר אנו מגדירים משתנים, אין לנו שליטה לגבי מיקומם בזיכרון - המהדר ומערכת ההפעלה קובעים זאת. העובדה שהמשתנה c הוגדר לפני המשתנה d, איננה מבטיחה אפילו שc יישב משמאל לd.
מציאת כתובות משתנים[]
אם כי איננו יכולים לקבוע היכן יישבו משתנים בזיכרון, אפשר לברר את כתובתם, לפי הצורה:
&varכאשר var הוא משתנה רגיל (למציאת כתובת מערך או מחרוזת, ראה הקשר בין מערכים למצביעים).
כפי שראינו בפלט, אפשר להדפיס כתובות מצביעים. נתבונן לדוגמה בקטע הקוד הבא:
char c = 'a';
printf("%p", &c);הקטע ידפיס את כתובת המשתנה c.
מחסנית הזיכרון[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
חזרה לניסיון כתיבת swap[]
כעת, לאחר שראינו את מבנה הזיכרון, הבה נחזור חזרה לניסיון הכושל לכתיבת swap שראינו. נניח שהמשתנה a מכיל את התו 'a', והמשתנה b מכיל את התו 'b'. המשתנים a וb יושבים במקומות כלשהם בזיכרון. כאשר נקרא לפונקציה swap, ייווצרו המשתנים x וy במקומות אחרים לחלוטין בזיכרון, וערכי המשתנים a וb יועתקו אליהם בהתאמה. הזיכרון עשוי להראות כך:

בסוף הפונקציה, אכן מוחלפים ערכיהם של x וy:

כעת ברור מדוע אין לכך שום השפעה על ערכי a וb.
מהם מצביעים?[]
משמעות מצביע[]
מצביע הוא משתנה שערכו כתובת בזיכרון, ייתכן שבפרט כתובת זיכרון שבו יושב משתנה אחר.
התרשים הבא, לדוגמא, מראה מצב אפשרי של הזיכרון כאשר יש שלושה משתנים:
- המשתנים c וd הם אלה שהוסברו מוקדם יותר.
- המשתנה p הוא מצביע למשתנה מסוג תו. הערך היושב בו הוא 2000, שהוא בדיוק כתובתו של c. אומרים שp מצביע על c.

בתרשימים מסוג זה, לרוב מסמנים חץ מהמשתנה המצביע למשתנה שאליו הוא מצביע:
הגדרה בקוד[]
מצהירים על מצביע כך:
<type> *<name>;כאשר type הוא סוג המשתנה שאל כתובתו מצביע משתנה זה (ראינו פירוט לגבי סוגים אלה בסוגי משתנים בסיסיים), וname הוא שמו של המצביע. (בנושא עניינים סגנוניים תוכל למצוא מספר נקודות סגנוניות והשקפות שונות לגבי הגדרת משתנים.)
נתבונן, לדוגמה, בקוד הבא:
char c = 'a';
int d;
char *p = &c;נשים לב לשורה השלישית. המשתנה p מוגדר כמצביע לתו. הוא מאותחל לכתובתו של c, ולכן הוא מצביע לp. אם נבקש לראות את הערך בתא ש p מצביע עליו נגלה שהוא מצביע על הערך 'a'.
כדי להגדיר מספר מצביעים (מאותו סוג) באותה שורה, רושמים כך:
int *p0, *p1;יעד ההצבעה[]
כפי שראינו, מצביע הוא פשוט משתנה שערכו כתובת בזיכרון. כמו כל משתנה אחר, אפשר לאתחל מצביע, ואפשר להשים לו ערך. כל פעולה כזו תשנה להיכן הוא מצביע.
לדוגמה:
int m0, m1;
int *p;
p = &m0;
p = &m1;כאן מוגדרים שלושה משתנים: m0 וm1 הם שלמים, וp הוא מצביע לשלם.
לאחר השורה
int *p;מכיל p ערך שרירותי כלשהו; מכנים זאת לעתים ערך זבל, שיכול להשתנות מריצה לריצה. הוא מצביע למקום שרירותי בזיכרון.
לאחר השורה:
p = &m0;מצביע p לm0:

m0 וm1 לא אותחלו, ולכן הם מכילים ערכי זבל. בפרט, בדוגמה זו, m0 מכיל את הערך 99322, וm1 מכיל את הערך 1334.
לאחר השורה:
p = &m1;מצביע p לm1:

כתובת האפס NULL[]
מצביע לא מאותחל מצביע למקום שרירותי בזיכרון. לפעמים אי אפשר לאתחל מצביע לכתובת חוקית. כדי לסמן שהמצביע אינו מצביע למקום חוקי בזיכרון, נהוג לאתחל אותו לכתובת 0. לשם הקריאות, יש המשתמשים בקבוע NULL שמוגדר כ0. כך, לדוגמה, שכיח לראות קוד כזה:
int *p = NULL;הכתובת NULL שימושית מאד. נדבר עוד עליה בהקצאת זיכרון דינאמית.
|
|
כדאי לדעת: כדי להשתמש בקבוע NULL, אפשר לרשום בראשי הקבצים המשתמשים בו:#include <stddef.h> . |
הערך המוצבע[]
כאשר מצביע מצביע לכתובת חוקית, אפשר לגשת לערך באותה כתובת. עושים כך בצורה הבאה:
*<ptr>כאשר ptr הוא שם המצביע.
נתבונן לדוגמה בקטע הקוד הבא:
int m0;
int *p = &m0;
int m1;
*p = 3;
m1 = m0 + *p;
p = &m1;
printf("%d %d %d", m0, *p, m1);
|
|
עכשיו תורך: נסה לחזות מה ידפיס הקוד. |
הפתרון
3 6 6
כמו שראינו מקודם, לאחר השורות:
int m0;
p = &m0;
int m1;מצביע p לm0:
m0 וm1 לא אותחלו, ולכן הם מכילים ערכי זבל. בפרט, שוב בדוגמה זו, m0 מכיל את הערך 99322, וm1 מכיל את הערך 1334.
השורה:
*p = 3;משימה למשתנה אליו מצביע p את הערך p. היות שp מצביע לm0, תשים השורה את הערך 3 לm0:

נתבונן בשורה:
m1 = m0 + *p;ערכו של m0 הוא 3; היות שp מצביע לm0, אז *p, כלומר הערך במשתנה אליו מצביע p, גם כן 3. סכומם הוא 6 כמובן, וזה הערך שיושם בm1:

השורה:
p = &m1;משימה לp את כתובתו של m1, ולכן יצביע p לm1:

שימוש במצביעים להעברת משתנים לפונקציה[]
בשפת C אפשר להעביר משתנים לפונקציות בשתי צורות. העברה by value מעתיקה ערך משתנים, והעברה by reference מעתיקה את כתובת המשתנים (על ידי מצביעים).
נחזור שוב לניסיון הכושל לכתיבת הפונקציה swap שראינו, אך עתה נפתור את הבעיה על ידי מצביעים. את הפונקציה swap נגדיר כעת כך:
void swap(int *px, int *py)
{
int temp = *px;
*px = *py;
*py = temp;
}הפונקציה מקבלת כעת שני מצביעים למספרים שלמים במקום שני מספרים שלמים.
נקרא כך לפונקציה:
char a = 'a', b = 'b';
swap(&a,&b);
printf("%c %c\n", a, b);כדי לקרוא לפונקציה כעת מעבירים שני כתובות למצביעים במקום שני ערכים שלמים.
הפלט של תוכנית זו יהיה "b a". כלומר, הערכים של המשתנים אכן הוחלפו. מדוע הצלחנו הפעם? נתבונן בשורה:
swap(&a,&b);שורה זו קוראת לפונקציה swap עם כתובותיהם של a וb. שוב מועתקים ערכים בקריאה לפונקציה, אך הפעם יש הבדל מהותי. היות שכתובות המשתנים הועתקו, אז px וpy אכן מצביעים למקום של המשתנים המקוריים. בתחילת הפונקציה swap, לכן, הזיכרון נראה כך:
במהלך הפונקציה מעתיקים בין ערכי המשתנים המוצבעים על ידי px וpy, ולכן בסוף הפונקציה, הזיכרון ייראה כך:

כשיוצאים מהפונקציה, לכן, ערכי המשתנים המקוריים הוחלפו, כפי שמראה פקודת ההדפסה.
זהירות בשימוש במצביעים[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
עניינים סגנוניים[]
מיקום הכוכבית בהגדרה[]
אפשר להגדיר מצביע על ידי כתיבת טיפוס המצביע, מספר רווחים, כוכבית, מספר רווחים, שם המצביע, ונקודה פסיק. כל ההגדרות הבאות, לכן, נכונות:
int *a_pointer;
int* another_pointer;
int * yet_another_pointer;עם זאת, נוהגים להשתמש רק בסגנון שבאחת משתי השורות הראשונות, ולכן נתמקד רק בהן. ישנם וויכוחים רבים לגבי הסגנון הנכון להגדרת מצביעים.
חסידי הסגנון שבשורה הראשונה מצביעים על הנקודה הבאה. נתבונן בקטע הקוד הבא:
int* p0, p1, p2;ונשים לב שרק p0 הוא מצביע (p1 וp2 הם משתנים רגילים מסוג int). המסקנה לדעתם היא שהסגנון בשורה השניה מבלבל.
חסידי הסגנון שבשורה השניה מצביעים על הנקודה הבאה. לרוב מגדירים משתנה בסגנון סוג שלאחריו רווח שלאחריו שם:
int a;המסקנה לדעתם היא שהסגנון בשורה הראשונה יוצא דופן, שכן אין רווח בין int * לבין a_pointer.
בחירת שמות למצביעים[]
ישנם סגנונות תכנות שלפיהם כל שם מצביע אמור להתחיל בp, או בp_; ישנם סגנונות (אחרים) לפיהם שם מצביע יכלול את הרצף ptr (קיצור של המילה pointer); ישנם סגנונות אחרים השוללים מוסכמות אלה. אין הכרעה חד משמעית בשאלות אלה.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מצביעים, מערכים, ופונקציות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C למצביעים יש מספר תכונות המקשרים אותם למערכים ופונקציות.
|
|
שימו לב: מומלץ ללמוד פרק זה רק לאחר שליטה טובה יחסית במצביעים. |
חשבון מצביעים[]
במשמעות מצביע ראינו שמצביע הוא פשוט משתנה שערכו כתובת בזיכרון; כלומר, אם ערך מצביע 2000, לדוגמה, אז יעד ההצבעה הוא הכתובת 2000. אין זה מפתיע, לכן, שאפשר לשנות את יעד ההצבעה על ידי פעולות חשבוניות. מה שמפתיע הוא שפעולות חשבוניות על מצביעים פועלות בחוקים שונים במקצת מאשר על משתני מספרים רגילים. את ההגיון לחוקים אלה נבין רק כשנגיע לקשר בין מצביעים למערכים.
חיבור מספר למצביע וחיסור מספר ממצביע[]
נתבונן בקטע הקוד הבא:
char c = 'a';
char *p = &c;
char *p_plus_1, *p_plus_2;
p_plus_1 = p + 1;
p_plus_2 = p + 2;השורות
p_plus_1 = p + 1;
p_plus_2 = p + 2;משתמשות בחשבון מצביעים. בפרט, מה משמעות p + 1 וp + 2? התרשים הבא מראה את התשובה לכך:

p + 1 וp + 2 הם מצביעים לתו אחד קדימה, ולשני תווים קדימה. אם p הוא מצביע לתו, והוא מצביע לכתובת 2000, אז p + 1 ערכו 2001, וp + 2 ערכו 2002.
עד כאן המצב זהה לחיבור רגיל, אולם כעת נראה משהו שונה. נתבונן בקטע הקוד הבא:
int c = 3;
int *p = &c;
int *p_plus_1, *p_plus_2;
p_plus_1 = p + 1;
p_plus_2 = p + 2;מה משמעות p + 1 וp + 2 כעת? התרשים הבא מראה את התשובה לכך:

p + 1 וp + 2 הם מצביעים לשלם אחד קדימה, ולשני שלמים קדימה. אם p הוא מצביע לשלם, והוא מצביע לכתובת 2000, אז במחשב שבו שלם תופס 4 בתים, p + 1 ערכו 2004, וp + 2 ערכו 2008.
נוכל לסכם זאת כך. אם p הוא מצביע לטיפוס t כלשהו, אז ערך p + i הוא ערך p ועוד i * sizeof(t). במילים אחרות, p + i מצביע לp ועוד i פעמים t קדימה.
באותו אופן גם חיסור שלם ממשתנה. אם p הוא מצביע לטיפוס t כלשהו, אז ערך p - i הוא ערך p פחות i * sizeof(t).. במילים אחרות, p - i מצביע לp ועוד i פעמים t אחורה.
הגדלה עצמית והקטנה עצמית של מצביע[]
לאחר שראינו מה משמעות חיבור וחיסור שלם למצביע, לא קשה לנחש את משמעותו של קוד כזה:
int *p = &m;
p++;ראינו בהגדלה עצמית והקטנה עצמית בפעולות חשבוניות שזוהי כתיבה מקוצרת לקוד:
int *p = &m;
p = p + 1;המשמעות של ארבע השורות הבאות, לכן:
p++;
++p;
p--;
--p;היא, בהתאמה:
- קידום בדיעבד של המצביע p לאיבר הבא
- קידום לכתחילה של המצביע p לאיבר הבא
- הסגה בדיעבד של המצביע p לאיבר הקודם
- הסגה לכתחילה של המצביע p לאיבר הקודם
הפרש בין מצביעים[]
ההפרש בין שני מצביעים מאותו סוג, הוא מספר האיברים ביניהם בזיכרון.
לדוגמה, נניח שp0 מצביע לכתובת 2008, p1 מצביע לכתובת 2000, אלה מצביעים לשלמים, ובמחשב זה תופס שלם 4 בתים. אז:
p0 - p1הוא 2.
ההפרש בין שני מצביעים מסוגים שונים אינו ניתן לחישוב בC - המהדר יתלונן על הניסיון לעשות זאת.
פעולות חשבוניות אחרות[]
אין אפשרות לבצע שום פעולה חשבונית אחרת על מצביעים. לדוגמה, אין אפשרות לחלק מצביע בקבוע, להכפיל מצביע במצביע, וכולי.
הקשר בין מצביעים למערכים[]
עד עתה התייחסנו למצביעים ולמערכים כשני דברים נפרדים, אך יש קשר הדוק ביניהם.
|
|
כדאי לדעת: גרסאותיה המוקדמות של שפת C כלל לא כללו מערכים כפי שאנו מכירים אותם היום. הקשר בין מערכים למצביעים נובע מגרסאות מוקדמות אלה. |
הקשר בין מערכים למצביעים מתגלה בשתי נקודות אלה:
- משתנה המוגדר כמערך הוא למעשה מצביע לאיבר הראשון במערך (ליתר דיוק, הוא מצביע קבוע לאיבר הראשון - מושג שנראה בהמשך).
- אפשר לגשת לערך מוצבע של מצביע בעזרת אינדקס, בדיוק כפי שעושים במערכים.
כעת נפרט במקצת שתי נקודות אלו.
המערך כמצביע[]
משתנה המוגדר כמערך הוא למעשה מצביע לאיבר הראשון במערך. הבה נראה דוגמה. נניח שאנו מצהירים על nums כמערך של שלמים:
int nums[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};שמו של המערך, nums, הוא מצביע לאיברו הראשון. הבה נבדוק זאת:
int nums[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int *p;
p = nums;
printf("%d", *p);אם נריץ את קטע הקוד, התכנית תדפיס 0. p מצביע לאיברו הראשון של nums, שהוא 0.
מהדוגמה הנ"ל, אגב, עולה שאפשר לגשת לכל איבר במערך גם בלי להשתמש באינדקס. לדוגמה, כדי לשנות את ערך איברו השלישי של המערך ל5000, נוכל לכתוב כך:
int nums[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int *p;
p = nums;
*(p + 2) = 5000;נוכל לכתוב אפילו ביתר קיצור, כך:
int nums[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int *p = nums;
*(p + 2) = 5000;או אפילו כך:
int nums[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
*(nums + 2) = 5000;במילים אחרות, צורת הכתיבה על ידי אינדקס:
nums[2] = 5000;היא תוספת שהוסיפו לשפה מטעמי נוחות בלבד, והיה אפשר להסתדר בלעדיה בעזרת מצביעים.
גישה למצביע כאל מערך[]
נתבונן בקטע הקוד הבא:
int m = 3;
int *p = &m;כיצד נוכל לשנות את ערכו של m על ידי p? עד עתה, ראינו שאפשר לעשות זאת באופן הבא:
*p = 5000;אך אפשר לעשות זאת גם בעזרת אינדקס, כך:
p[0] = 5000; /* This changes m to 5000. */
השפה, אגב, אינה מגבילה זאת רק לאינדקס 0. נוכל לכתוב גם את הקוד המסוכן הבא:
int m = 3;
int *p = &m;
/* This is a dangerous line! "*/
p[2] = 5000;כאן משנים את הערך בזיכרון של קטע זיכרון שנמצא 2 מספרים שלמים לאחר m. מה יושב בקטע זיכרון זה? איננו יודעים, ולכן זו טעות לעשות זאת. נדון בזאת בזהירות בשימוש במצביעים.
מצביעים קבועים[]
במשתנים קבועים ראינו שאפשר להצהיר על משתנים שאין אפשרות לשנות את ערכם. הדבר חשוב במיוחד כשמשתנים אלה הם מצביעים.
ארבעת סוגי המצביעים הקבועים[]
מצביעים הם משתנים ששני ערכים קשורים אליהם: יעד ההצבעה, והערך המוצבע. מה משמעות מצביעים קבועים, אם כן? אפשר לחשוב על שתי אפשרויות:
- מצביעים שאין אפשרות לשנות את יעד ההצבעה שלהם.
- מצביעים שאין אפשרות לשנות את הערך המוצבע שלהם.
שפת C מאפשרת להגדיר מצביעים כקבועים לכל אחת מארבעת השילובים האפשריים. נניח שt הוא טיפוס (לדוגמה, int), וname הוא שם. אז:
<t> *<name>מגדיר משתנה שמותר לשנות את יעד ההצבעה שלו, ומותר לשנות את הערך המוצבע שלו.
<t> *const <name>מגדיר משתנה שאסור לשנות את יעד ההצבעה שלו, ומותר לשנות את הערך המוצבע שלו.
const <t> *<name>מגדיר משתנה שמותר לשנות את יעד ההצבעה שלו, ואסור לשנות את הערך המוצבע שלו.
const <t> *const <name>מגדיר משתנה שאסור לשנות את יעד ההצבעה שלו, ואסור לשנות את הערך המוצבע שלו.
התוכנית הבאה, לדוגמה, חוקית:
char a;
const char b = 'b';
char *p = &a;
*p = 'c';התוכנית הבאה אינה חוקית:
char a;
const char b = 'b';
char *const p = &a;
p = &b; /* Error: can't change the destination of p! */גם התוכנית הבאה אינה חוקית:
char a;
const char b = 'b';
const char *p = &b;
*p = 'c'; /* Error: can't change the value pointed by p! */הקשר להעברת משתנים לפונקציות[]
הבה נכתוב פונקציה שמוצאת כמה פעמים מופיעה הספרה 3 בחלק של מערך. לדוגמה, אם המערך הוא
int a[] = {0, 1, 3, 2, 2, 3, 4, 5};ורוצים לדעת כמה פעמים מופיעה 3 ב4 האיברים הראשונים שלו, אז התשובה היא 1. להלן פיתרון בעייתי:
int how_many_times_3_appears(int *p, int len)
{
int i;
int count = 0;
for(i = 0, count = 0; i < len; ++i)
if(*p = 3) /* This is wrong! */
++count;
return count;
}
int main()
{
int a[] = {0, 1, 3, 2, 2, 3, 4, 5};
int count = how_many_times_3_appears(a, 4);
return 0;
}נשים לב שבטעות ביצענו השמה במקום בדיקת שוויון בשורה:
if(*p = 3) /* This is wrong! */ולכן הקריאה פשוט תרשום 3 בארבעת המקומות הראשונים במערך.
נחשוב שוב על הפונקציה how_many_times_3_appears. האם היא אמורה לשנות את הערכים המועברים אליה? לא. הבה נודיע זאת למהדר:
/* Note that p points to something that cannot be changed. */
int how_many_times_3_appears(const int *p, int len)
{
int i;
int count = 0;
for(i = 0, count = 0; i < len; ++i)
if(*p = 3) /* This is wrong! */
++count;
return count;
}כעת, אם בטעות נשגה כמקודם, המהדר יתלונן על השורה:
if(*p = 3) /* This is wrong! */ואנו נוכל לתקן אותה:
if(*p == 3)
מצביעים לפונקציות[]
|
|
שקול לדלג על נושא זה מומלץ לשקול לדלג על נושא זה בפעם הראשונה בה נתקלים בו, ולחזור אליו רק לאחר מעבר כללי על כל הספר. |
מהו מצביע לפונקציה?[]
במהם מצביעים? ראינו שמצביע הוא משתנה שיכול הצביע על כתובת בזכרון בו יושב משתנה או קבוע. גם פונקציות יושבות בזכרון המחשב. השפה מאפשרת, לכן, גם להגדיר משתנים שמצביעים על כתובות זכרון בהן יושבות פונקציות.
הגדרת מצביע לפונקציה[]
מגדירים מצביע לפונקציה בצורה:
<return_type> (*<ptr_name>)([args]);כאשר return_type הוא סוג הערך המוחזר, ptr_name הוא שם המצביע, וargs הם הארגומנטים שאותה מקבלת הפונקציה.
כך, לדוגמה, מגדירים מצביע בשם print_fn לפונקציה שאינה מקבלת אף ערך, ואינה מחזירה אף ערך:
void (*print_fn)();כך, לדוגמה, אפשר להגדיר מצביע לפונקציה בשם input_fn שאינה מקבלת אף פרמטר, ומחזירה שלם:
int (*input_fn)();כאשר מגדירים מצביע לפונקציה שמקבלת ארגומנטים, אין חשיבות לשם המשתנים. הנה, לדוגמה, הגדרת מצביע בשם op_fn שמקבל שני מספרי נקודה צפה:
float (*op_fn)(float a, float b);לפי חוקי השפה, הכוונה היא שop_fn מצביע לפונקציה שמקבלת שני מספרי נקודה צפה, ומחזירה נקודה צפה, 'לאו דווקא בשמות a וb. אפשר להגדיר, לכן, את op_fn גם בצורה הבאה, השקולה לחלוטין לצורה הקודמת:
float (*op_fn)(float foo, float bar);למעשה, אין צורך אפילו להגדיר את שמות הארגומנטים בפונקציה שאליה מצביעים:
float (*op_fn)(float, float);שימוש בtypedef[]
אפשר להשתמש בtypdef כדי להגדיר שם נרדף לטיפוס חדש של מצביע לפונקציה. עושים זאת בצורה הבאה:
typedef <return_type> (*<type_name>)([args]);כאשר return_type הוא סוג הערך המוחזר, type_name הוא שם הטיפוס החדש, וargs הם הארגומנטים שאותה מקבלת הפונקציה.
אפשר, לכן, להחליף את השורות הבאות:
void (*print_fn)() = &print_3;
float (*op_fn)(float foo, float bar);בשורות:
typedef void (*print_fn_ptr)();
typedef float (*op_fn_ptr)(float, float);
print_fn_ptr print_fn;
op_fn_ptr op_fn;קריאה לפונקציה דרך מצביע[]
קוראים למצביע לפונקציה בצורה הבאה:
(*<fn_ptr>)([args])כאשר fn_ptr הוא שם המצביע לפונקציה, וargs הם ערכי הארגומנטים. הקריאה היא קריאה לפונקציה לכל דבר. בפרט, אם הפונקציה מחזירה ערך, אז גם קריאה דרך מצביע תחזיר ערך. הערה: כאן נעשה שימוש בצורה ptr = &func (כאשר ptr הוא מצביע מסויים ו-func - כתובת הפונקציה בזיכרון). באופן שקול, ניתן לרשום {{{1}}} (כלומר, ללא הסימן "&") והתוצאה תהייה זהה לחלוטין.
להלן דוגמה:
#include <stdio.h>
void print_2()
{
printf("2");
}
float add(float x, float y)
{
return x + y;
}
int main()
{
void (*print_fn)() = &print_2;
float (*op_fn)(float x, float y) = &add;
/* Prints 2. */
(*print_fn)();
/* Prints 5.0. */
printf("%f", (*op_fn)(2, 3) );
return 0;
}מצביעים לפונקציות כארגומנטים[]
אפשר להעביר מצביעים לפונקציות כארגומנטים לפונקציות אחרות. להלן דוגמה:
#include <stdio.h>
#include <conio.h>
void print_2()
{
printf("2");
}
void print_3()
{
printf("3");
}
void do_something_after_keypress(void (*fn)())
{
getch();
(*fn)();
}
int main()
{
do_something_after_keypress(print_2);
do_something_after_keypress(print_3);
return 0;
}הפונקציה do_something_after_keypress מקבלת ארגומנט יחיד, fn, שהוא מצביע לפונקציה שאינה מקבלת ארגומנטים ואינה מחזירה דבר. הפונקציה מחכה ללחיצת כפתור, ולאחר מכן מפעילה את הפונקציה שאותה קיבלה כארגומנט:
void do_something_after_keypress(void (*fn)())
{
getch();
(*fn)();
}השורות הבאות בפונקציה main יגרמו לפונקציה לחכות ללחיצת מקש ואז להדפיס 2, ולכחות ללחיצת מקש ואז להדפיס 3:
do_something_after_keypress(&print_2);
do_something_after_keypress(&print_3);
|
|
כדאי לדעת: כאן ראינו שליחת מצביע לפונקציה כארגומנט, כדי שתיקרא בכל פעם שנלחץ מקש. הטכניקה של שליחת מצביע לפונקציה כארגומנט, כדי שתיקרא בכל פעם שמתרש אירוע - נקראת callback. זו טכניקה נפוצה מאד בספריות, בפרט בספריות ממשק גרפי, לדוגמה gtk. |
מצביעים לvoid[]
|
|
שקול לדלג על נושא זה מומלץ לשקול לדלג על נושא זה בפעם הראשונה בה נתקלים בו, ולחזור אליו רק לאחר מעבר כללי על כל הספר. |
שימוש[]
|
|
כדאי לדעת: בשפת C משמשת המילה השמורה void גם במשמעות שונה לחלוטין, שאותה ראינו בפונקציה בלי ערך מוחזר. אין להתבלבל בין שתי משמעויות נפרדות אלה - הן שונות זו מזו. |
מצביע מסוג void * הוא מצביע שסוג הזיכרון אליו הוא מצביע אינו מוגדר. נתבונן על דוגמה פשוטה להשמה של מצביע כזה:
int j = 2;
int *i = &j;
void *p = i;המשתנה p מצביע אל אותה הכתובת אליה מצביע i. גם קטע הקוד הבא הוא חוקי:
int j = 3;
void *p = &j;כאן המשתנה p מצביע ישירות לכתובת הזיכרון של j. אפילו קטע הקוד הבא הוא חוקי:
int j = 1;
double d = 1.5;
void *p;
p = &j;
p = &d;המשתנה p הצביע על משתנה מטיפוס int, ואז עבר להצביע על משתנה מטיפוס double, ללא צורך בשום המרה. מצביע מטיפוס void * נותן חופש רב מאוד: לא צריך להצהיר על סוג המשתנה עליו מצביעים.
מגבלות[]
נסו להריץ את קטע הקוד הבא:
int j = 1;
void *p;
p = &j;
printf("%d", *p);הקטע כלל לא יעבור הידור. החופש שמציעים מצביעים מטיפוס זה עולה במחיר: לא ניתן לגשת לתוכן של מצביעים מטיפוס void *. הסיבה פשוטה: המהדר לא מסוגל לדעת לאיזה גודל של זיכרון לגשת, שהרי למשל - בלוק זיכרון המכיל int הוא לא באותו גודל כמו בלוק זיכרון המכיל char. לכן, לפני שניתן לגשת לתוכן מצביע מסוג void * - צריך להמיר אותו למצביע מסוג ידוע, ורק אז ניתן לגשת או לשנות את תוכנו.
לכן:
- מצביע מטיפוס void * יכול להצביע על כל סוג משתנה שהוא.
- לא ניתן לבצע שום פעולה שדורשת מהמהדר לדעת את נפח הזיכרון עליו אנו מצביעים: אי אפשר לגשת לתוכן המצביע - לא לקרוא ולא לכתוב.
גישה[]
כאמור, כדי לגשת למצביעים מטיפוס void *, יש להמיר אותם קודם. נראה כאן דוגמה להמרה כזאת:
char c = '!';
void *p = &c;
char *cp = (char *) p;
printf("%c", *cp);ניתן לעשות זאת גם ללא מצביע עזר, בצורה הבאה:
char c = '?';
void *p = &c;
printf("%c", *((double *) p));הצורך במצביע לטיפוס לא ידוע[]
משתנים מטיפוס void * אינם נוחים לצורכי עבודה שוטפת. הצורך העיקרי במצביעים ל-void הוא בכתיבת פונקציות גנריות, דהיינו - פונקציות ותוכניות המיועדות לשימוש עם מגוון של משתנים. נתבונן על דוגמה מוכרת: בשימוש במצביעים להעברת משתנים לפונקציה ראינו כיצד לכתוב פונקציית swap המחליפה בין ערכי שני משתנים מטיפוס שלם. עם זאת, הוטלה על המצביעים הללו מגבלה: הם חייבים להצביע למשתנה מסוג ידוע כלשהו (למשל - int *). בכדי להתגבר על מגבלה זו, ניתן להשתמש במצביעים מטיפוס void *. סוג זה של מצביעים מאפשר להצביע על משתנים מכל סוג שהוא. בפיסקה הבאה נראה דוגמה איך כותבים פונקציית החלפה כללית.
המרה למצביע לתו[]
דרך לעבודה עם מצביעים ל-void * ללא המרה היא התייחסות אליהם כזיכרון גולמי. זה שימושי בדוגמה כמו זו שהבאנו קודם - פונקצייה שמחליפה בין התכנים אליהם מצביעים שני משתנים מטיפוס לא ידוע. כדי לעבוד בצורה כזאת, נתייחס למצביעים כאילו הם מטיפוס unsigned char. נעיר כאן כי גודלו של משתנה מטיפוס תו (char) הוא 1 על פי הגדרה (בניגוד לסוגים אחרים בהם הגודל עשוי להיות שונה בפלטפורמות שונות). נראה כאן דוגמה לתוכנית עם פונקציית החלפה כזאת:
#include <stdio.h>
void MySwap(void *a, void *b, size_t size)
{
int i;
unsigned char *tmpA = (unsigned char *) a, *tmpB = (unsigned char *) b;
for(i=0; i<size; i++)
{
unsigned char tmp = *tmpA;
*tmpA = *tmpB;
*tmpB = tmp;
++tmpA;
++tmpB;
}
}
int main()
{
int i = 2, j = 4;
printf("A: %d B: %d\n", i, j);
MySwap(&i, &j, sizeof(int));
printf("A: %d B: %d\n", i, j);
float d1 = 1.5, d2 = 3.2;
printf("A: %g B: %g\n", d1, d2);
MySwap(&d1, &d2, sizeof(float));
printf("A: %g B: %g\n", d1, d2);
printf("Messy swap: A: %g B: %d\n", d1, i);
MySwap(&d1, &i, sizeof(int));
printf("Messy swap: A: %d B: %g\n", i, d1);
return 0;
}פונקציית ההחלפה מקבלת מצביעים שתוכנם לא ידוע (ולא משנה), ומבצעת שלוש החלפות. שתי ההחלפות הראשונות הן תקינות לגמרי. ההחלפה השלישית היא דוגמה למצב ממנו יש להימנע: היא מחליפה בין שני משתנים שגודלם שונה והתוצאה היא לא רצויה, כאשר לא מתקבלת על כך שום אזהרה מהתוכנית.
דוגמה נוספת - העתקת קטעי זיכרון[]
זוהי פונקציה דומה, שתפקידה להעתיק קטעי זיכרון. חדי העין ישימו לב לדמיון לפונקציה המוכרת strcpy, עם תוספת ארגומנט של גודל המשתנים.
#include <stdio.h>
void setElement(void *dest, void *src, size_t size)
{
int i;
unsigned char *tmpA = (unsigned char *) src, *tmpB = (unsigned char *) dest;
for(i=0; i<size; i++)
{
*tmpB = *tmpA;
++tmpA;
++tmpB;
}
}
int main()
{
char str1[] = {'H', 'e', 'l', 'l', 'o', '\0'};
char str2[6];
setElement(str2, str1, 6);
printf("%s\n", str2);
return 0;
}פונקציית הספריה memcpy[]
למטרות העתקת קטעי זיכרון, קיימת פונקציה בספריה הסטנדרטית בשם memcpy. כדי להשתמש בה יש להכליל את string.h. הפונקציה הזו מקבלת ארגומנטים זהים לזו שמקבלת הפונקציה שראינו למעלה: מצביע לתא זיכרון שהוא היעד (חובה עלינו לדאוג שהוא פנוי - הפונקציה לא בודקת זאת בעצמה), מצביע לתא זיכרון ממנו מעתיקים, ומספר התאים אותם יש להעתיק. נראה שימוש לדוגמה:
#include <stdio.h>
#include <string.h>
int main()
{
char str1[] = {'H', 'e', 'l', 'l', 'o', '\0'};
char str2[6];
memcpy(str2, str1, 6);
printf("%s\n", str2);
return 0;
}במקרה ויש צורך להעתיק קטעי זיכרון רציפים - רצוי לעשות זאת עם memcpy, כיוון שהיא פועלת בצורה יעילה יותר מהעתקה כפי שראינו קודם, בעזרת לולאה.
שימוש יחד עם מצביעים לפונקציות[]
בעזרת שימוש משולב במצביעים לפונקצייה, ומצביעי void *, ניתן לבנות תוכניות גנריות - תוכניות המיועדות לכל סוג של משתנה, זאת באמצעות העברה של מצביעי void * ומצביעים לפונקציה המתאימה. נראה דוגמה לתוכנית פשוטה המשווה בין סוגי משתנים שונים:
#include <stdio.h>
#include <string.h>
typedef struct {
char name[10];
int age;
} Person;
// Compare Integers
int CompareInts(const void *a, const void *b) {
int numA = *(int *)a;
int numB = *(int *)b;
if(numA == numB) return 0;
if(numA > numB) return 1;
return -1;
}
// Compares two people by their age
int ComparePeople(const void *a, const void *b) {
Person personA = *(Person *)a;
Person personB = *(Person *)b;
if(personA.age == personB.age) return 0;
if(personA.age > personB.age) return 1;
return -1;
}
// Compare and prints the results
void Compare(const void *a, const void *b, int (*func) (void *, void *)) {
int cmp;
cmp = func(a, b);
if(cmp == 0) printf("Equal\n");
else if(cmp < 0) printf("B is bigger\n");
else printf("A is bigger\n");
}
int main()
{
int i = 2, j = 5;
Person p1, p2;
strcpy(p1.name, "David");
p1.age = 29;
strcpy(p2.name, "Shlomo");
p2.age = 25;
Compare(&i, &j, CompareInts);
Compare(&p1, &p2, ComparePeople);
return 0;
}הפונקציה Compare משווה בין סוגי משתנים שונים, שאינם מוגדרים מראש, זאת - בעזרת קבלה של פונקציה מתאימה עבור כל משתנה. לעיתים, נזדקק גם להעברה של גודל המשתנה (אם, למשל, נרצה לעבור על מערך של משתנים מטיפוס לא ידוע). פונקציה כזו לדוגמה היא פונקציית המיון המהיר שמגיעה עם הספרייה הסטנדרטית. נראה דוגמה לשימוש בה:
#include <stdio.h>
#include <stdlib.h>
// Compare Integers
int CompareInts(const void *a, const void *b) {
int numA = *(int *)a;
int numB = *(int *)b;
if(numA == numB) return 0;
if(numA > numB) return 1;
return -1;
}
void PrintIntArray(int *arr, int size) {
int i;
for(i=0; i<size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[5] = {3, 7, 9, 1, -4};
PrintIntArray(arr, 5);
qsort(arr, 5, sizeof(int), CompareInts);
PrintIntArray(arr, 5);
return 0;
}הפונקציה מקבלת מצביע לתחילת מערך, גודל המערך, גודל כל תא במערך, ופונקציית השוואה, ומסדרת את המערך.
בעייתיות[]
יחד עם היתרונות, תכנות בעזרת מצביעי void * בעייתי מכמה סיבות:
- נוחות ובטיחות - הצורך להעביר ארגומנטים רבים אינו נוח ומקשה על המשתמש. גרוע מכך - אין דרך לוודא את נכונות המידע המועבר, אלא רק בזמן הריצה. אם משתמש יזין מצביע לפונקציה לא מתאימה - התוכנית תקרוס בזמן הריצה.
- יעילות - אופן השימוש מכריח ביצוע המרות רבות של משתנים, פעולה שעולה במחיר של זמן ריצה.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מבנים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C מבנה (struct בלעז) הוא טיפוס חדש המוגדר על ידי המתכנת. בשונה ממערך, מבנה יכול להכיל טיפוסים שונים של משתנים, והגישה אליהם אינה מספרית אלא שמית.
|
|
כדאי לדעת: בניהול זיכרון דינאמי נעסוק במעט על מבנים והנדסת תוכנה. |
הצורך במבנים[]
נחשוב על תוכנית לניהול מלאי של חנות. בחנות יש סוגי פריטים שונים, שלכל אחד מהם מספר קטלוגי משלו, שם, מחיר, וכמות (כלומר, כמה יש בחנות כעת). אנו רוצים ליצור בסיס נתונים לטיפול במידע הזה, למשל לעדכון מחיר של פריט, לעדכון כמות פריט במקרה של מכירה, וכדומה. בפרט, היינו רוצים לשמור מערך שכל אחד מאיבריו יתאר פריט.
שפת C אינה כוללת טיפוס מתאים לתיאור פריט במלאי החנות - כל אחד מטיפוסי השפה יכול לתאר דברים פשוטים מאד בלבד (כמו מספרים). בפרק זה נראה כיצד להגדיר טיפוסים חדשים ולהשתמש בהם.
מהו מבנה?[]
מבנה הוא טיפוס חדש, שאנו מגדירים את שמו ומרכיביו כרצוננו. למבנה יש שדות, שהם איברים בעלי טיפוסים ושמות שאנו בוחרים.
לדוגמה, בדוגמה שראינו בצורך במבנים, נרצה ליצור טיפוס חדש שייקרא store_item. מבנה זה יכיל את השדות הבאים:
- מספר קטלוגי, מסוג שלם
- שם, מסוג מחרוזת בעלת 20 תווים לכל היותר
- מחיר, מסוג נקודה צפה
- כמות (כמה יש במלאי), מסוג שלם לא-שלילי
הגדרת מבנה[]
מגדירים מבנה בצורה הבאה:
struct <name>
{
[fields]
};כאשר name הוא שם המבנה, וfields היא רשימה של שדות. כל שדה הוא הצהרה על משתנה שהוא איבר של המבנה.
לדוגמה, בדוגמה שראינו בצורך במבנים, נגדיר את המבנה כך:
struct item
{
int catalog_number;
char name[20];
float price;
unsigned int num;
};אין חשיבות מיוחדת לסדר השדות בתוך המבנה - נוכל לקבוע אותו כרצוננו.
הגדרת המבנה הנ"ל מודיעה למהדר שיש כעת טיפוס חדש, ששמו struct item. בדיוק כפי שישנם int, char, וfloat, לדוגמה, כך גם יש כעת טיפוס בשם struct item.
משתנים מהטיפוס החדש[]
לאחר שהגדרנו את הטיפוס החדש, נוכל להשתמש בו כמו בכל טיפוס אחר.
נוכל, לדוגמה, ליצור משתנה חדש מסוגו בדיוק כמו מכל טיפוס אחר:
struct item shoko;נוכל גם ליצור מצביע לטיפוס זה:
struct item *p;ונוכל גם ליצור מערך מטיפוסו:
struct item items[300];גישה לשדות המבנה[]
גישה לשדות משתנה[]
ניגשים לשדות משתנה בצורה:
<name>.<field_name>כאשר name הוא שם המשתנה, וfield_name הוא שם השדה.
לדוגמה, נניח שshoko הוא משתנה מסוג struct item.
כדי לקבוע את מחירו ל12.90, נכתוב:
shoko.price = 12.90;כדי לקבוע את שמו כ"shoko", נכתוב:
strcpy(shoko.name, "shoko");כדי להדפיס את שמו ואת מחירו, נכתוב:
printf("The price of %s is %f", shoko.name, shoko.price);גישה לשדות מצביע[]
נניח שp הוא מצביע למבנה. נוכל לגשת לאיבר שלו בצורה:
*(p.<field_name>)לדוגמה, אם p הוא מצביע לstruct item, אז את שלוש הדוגמאות הקודמות אפשר לכתוב כך:
*(p.price) = 12.90;
strcpy(*(p.name), "shoko");
printf("The price of %s is %f", *(p.name), *(p.price));
גישה למבנה על ידי מצביע היא מהפעולות השכיחות בשפת C. השפה לכן כוללת את הצורה המקוצרת:
p-><field_name>שמשמעותה זהה. נוכל, לכן, לכתוב את שלוש הדוגמאות בצורה קצרה יותר:
p->price = 12.90;
strcpy(p->price, "shoko");
printf("The price of %s is %f", p->name, p->price);גישה לשדות איבר מערך[]
ניגשים לשדות איבר במערך בדיוק באופן שבו ניגשים לשדות משתנה. לדוגמה:
/* An array of 30 items. */
struct item items[30];
/* Access the 2nd item. */
items[1].price = 12.90;
strcpy(items[1].name, "shoko");
printf("The price of %s is %f", items[1].name, items[1].price);דוגמאות ביניים[]
נראה כעת מספר דוגמאות של פונקציות המקבלות מצביעים למבנים ופועלות עליהן.
הפונקציה הראשונה מקבלת מצביע לפריט ותוספת מחיר, ומעלה את מחיר הפריט בתוספת:
void raise_price(struct item *p, float amount)
{
p->price += amount;
}הפונקציה הבאה שנכתוב מקבלת מצביע לפריט, ומספר הפריטים שרוצים לקנות מתוכו. היא מעדכנת את מספר הפריטים, ומחזירה את המחיר הכולל שיש לשלם על הקניה:
float update_num(struct item *p, unsigned int how_many)
{
how_many = p->num < how_many? p->num : how_many;
p->num -= how_many;
return p->price * how_many;
}הפונקציה האחרונה שנכתוב כאן מקבלת מצביע לפריט, ומדפיסה למסך את נתוניו. להלן הצעה להצהרה לה:
void print_item(struct item *p);
|
|
עכשיו תורך: מה חשוד בהצהרה הקודמת? |
פתרון
נזכר במה שראינו במצביעים קבועים. הגיוני שפונקציה שמדפיסה פריט - לא תשנה את פרטיו. כדאי לשנות את ההצהרה כדי להדגיש שמדובר במצביע לפריט שאסור לשנותו, כך:
void print_item(const struct item *p);
נשנה כעת את ההצהרה, ונכתוב את הפונקציה:
void print_item(const struct item *p)
{
printf("name: %s, catalog number: %d, price: %f, in stock: %d\n", p->name, p->catalog_number, p->price, p->num);
}אתחול מבנה[]
לעתים, כאשר מייצרים משתנה מסוג מבנה, יש לתת ערך התחלתי לאיבריו. לדוגמה, נניח שמייצרים משתנה מסוג struct item שמתאר שוקו. ייתכן שנרצה לתת ערך התחלתי לאיבריו כך שמספרו הקטלוגי הוא 23, שמו הוא "shoko", מחירו הוא 12.90, ויש 100 יחידות שלו במלאי.
כפי שראינו מקודם בגישה לשדות המבנה, אפשר לגשת לכל אחד משדות המשתנה. נוכל, לכן, להשתמש בהשמה לכל אחד מאיבריו:
struct item shoko;
shoko.catalog_number = 23;
shoko.price = 12.90;
strcpy(shoko.name, "shoko");
shoko.num = 100;נראה בנושא זה דרכים קצרות יותר לעשות כן.
אתחול פרטני[]
לצורך אתחול המבנה בלבד, השפה מאפשרת צורה מקוצרת יותר (בדומה מאד למה שראינו באתחול מערך) מאשר השמה איבר אחר איבר:
struct item shoko = {23, "shoko", 12.90, 100};כאן יש לשים לב לסדר האיברים: הוא צריך להיות זהה לסדר שלפיו הוצהרו השדות במבנה.
אפשר גם לאתחל מערך של מבנים. לדוגמה:
struct item items[3] = {{23, "shoko", 12.90, 100}, {109, "roll", 5, 100}, {22, "kartiv", 2.3, 100}};
אתחול ממבנה אחר[]
אפשר לאתחל מבנה ישירות ממבנה אחר.
נתבונן לדוגמה בקוד הבא:
struct item shoko = {23, "shoko", 12.90, 100};
struct item temp = shoko;השורה:
struct item temp = shoko;שקולה לאתחול:
struct item temp = {shoko.catalog_number, shoko.price, shoko.name, shoko.num};שימוש בtypedef[]
השימוש בtypdef יכול לקצר הצהרות על משתני מבנים. היות שכל מבנה שאנו מגדירים הוא טיפוס, אפשר להשתמש בtypdef כדי לתת לו שם נרדף נוח יותר.
הבעיה[]
נתבונן שוב בדוגמאות למשתנים מהטיפוס החדש:
struct item shoko;
struct item *p;
struct item items[300];שמו של הטיפוס הוא struct item (שתי מילים), ולכן כל אחת מההצהרות ארוכה יחסית. שפת C ידועה בקצרנותה הרבה. אם הקוד מכיל הצהרות רבות כאלה, עלול הדבר להחשב כאריכות יתר.
פתרון א'[]
נוכל להשתמש בtypedef בלי לשנות את הגדרת המבנה שכבר ראינו:
struct item
{
int catalog_number;
char name[20];
float price;
unsigned int num;
};לאחר הגדרה זו, פשוט נרשום:
typedef struct item store_item;וכך ייצרנו "שם נרדף", store_item, לstruct item.
פתרון ב'[]
הפתרון השני מתבסס על כך שאנו יכולים להכניס את הגדרת המבנה לתוך הפקודה typedef, כך:
typedef struct
{
int catalog_number;
char name[20];
float price;
unsigned int num;
} store_item;גם כך ייצרנו "שם נרדף", store_item, למבנה שכרגע הגדרנו.
התוצאה[]
בין אם בחרנו בדרך א' והן אם בחרנו בדרך ב', קבלנו שם נרדף בעל מילה אחת. נוכל לכתוב כעת הצהרות כאלו:
store_item shoko;
store_item *p;
store_item items[300];דוגמת המשך[]
נמשיך בדוגמה פשוטה, שתסכם את רוב מה שלמדנו על מבנים.
התוכנית הבאה היא תוכנת ניהול פשוטה מאד לחנות מכולת:
#include <stdio.h>
struct item
{
int catalog_number;
char name[20];
float price;
unsigned int num;
};
float update_num(struct item *p, unsigned int how_many)
{
how_many = p->num < how_many? p->num : how_many;
p->num -= how_many;
return p->price * how_many;
}
void print_item(const struct item *p)
{
printf("name: %s, catalog number: %d, price: %f, in stock: %d\n", p->name, p->catalog_number, p->price, p->num);
}
int main()
{
struct item items[6] = {
{23, "shoko", 12.90, 100},
{109, "roll", 5, 100},
{22, "kartiv", 2.3, 5},
{33, "mastik", 1.0, 10},
{1000, "pita", 5, 1000},
{2233, "humus", 23, 20},
};
char reply;
do
{
unsigned int i;
printf("The items in the store are:\n");
for(i = 0; i < 6; ++i)
print_item(&items[i]);
printf("Which item would you like to purchase? ");
scanf("%ld", &i);
if(i > 6)
printf("This is not a valid item!\n");
else
update_num(&items[i], 1);
printf("Please type 'q' to quit, or anything else to continue: ");
scanf("%c", &reply);
printf("\n");
}
while(reply != 'q');
return 0;
}
ראשית, הנה הגדרת מבנה הפריט ומספר פונקציות העזר שכבר ראינו:
struct item
{
int catalog_number;
char name[20];
float price;
unsigned int num;
};
float update_num(struct item *p, unsigned int how_many)
{
how_many = p->num < how_many? p->num : how_many;
p->num -= how_many;
return p->price * how_many;
}
void print_item(const struct item *p)
{
printf("name: %s, catalog number: %d, price: %f, in stock: %d\n", p->name, p->catalog_number, p->price, p->num);
}כעת לפונקציה main, המנהלת את הפריטים:
int main()
{
struct item items[6] = {
{23, "shoko", 12.90, 100},
{109, "roll", 5, 100},
{22, "kartiv", 2.3, 5},
{33, "mastik", 1.0, 10},
{1000, "pita", 5, 1000},
{2233, "humus", 23, 20},
};
char reply;
do
{
unsigned int i;
printf("The items in the store are:\n");
for(i = 0; i < 6; ++i)
print_item(&items[i]);
printf("Which item would you like to purchase? ");
scanf("%ld", &i);
if(i > 6)
printf("This is not a valid item!\n");
else
update_num(&items[i], 1);
printf("Please type 'q' to quit, or anything else to continue: ");
scanf("%c", &reply);
printf("\n");
}
while(reply != 'q');
return 0;
}ראשית מגדירים את תכולת המלאי, המכיל 6 סוגי פריטים:
struct item items[6] = {
{23, "shoko", 12.90, 100},
{109, "roll", 5, 100},
{22, "kartiv", 2.3, 5},
{33, "mastik", 1.0, 10},
{1000, "pita", 5, 1000},
{2233, "humus", 23, 20},
};הלולאה:
char reply;
do
{
..
printf("Please type 'q' to quit, or anything else to continue: ");
scanf("%c", &reply);
printf("\n");
}
while(reply != 'q');פועלת כל עוד לא הקליד המשתמש 'q'.
בתוך הלולאה, ראשית מדפיסים את הפריטים:
printf("The items in the store are:\n");
for(i = 0; i < 6; ++i)
print_item(&items[i]);לאחר מכן מבקשים מהמשתמשת את הפריט שברצונה לרכוש:
printf("Which item would you like to purchase? ");
scanf("%ld", &i);כל שנותר הוא (לבדוק אם הפריט חוקי ו) לטפל בבקשה:
if(i > 6)
printf("This is not a valid item!\n");
else
update_num(&items[i], 1);מבנים ומצביעים[]
|
|
שקול לדלג על נושא זה נושא זה שימושי בעיקר רק אם אתה חש נוח עם מצביעים. אם לא, מומלץ לחזור לכאן לאחר שתשיג שליטה טובה יותר במצביעים. בכל מקרה, מומלץ שתחזור לכאן לפני ניהול זיכרון דינאמי. |
כתובת שדה[]
אפשר למצוא כתובת שדה בצורה:
&s.fכאשר s הוא שם המשתנה, וf הוא שם השדה.
לדוגמה:
struct foo
{
short int c;
int m;
};struct foo s;
int *p = &s.m;שדות מצביעים[]
שדות יכולים להיות מכל טיפוס שהוא, בולל, בין היתר, מצביעים. בקטע הקוד הבא, לדוגמה:
struct foo
{
...
char *p;
...
};p הוא שדה של struct foo, וטיפוסו הוא מצביע לתו. קטע הקוד הבא מראה כיצד להשתמש בו:
struct foo f;
char a = 3;
f.p = &a;
/* This makes the value of a be 3. */
*f.p = 3;
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
ניהול זיכרון דינאמי
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
| |
הערך נמצא בשלבי עריכה הנכם מתבקשים שלא לערוך ערך זה בטרם תוסר הודעה זו כדי למנוע התנגשויות עריכה. שימו לב! אם דף זה לא נערך במשך שבוע, רשאי כל ויקיפד להסיר את התבנית ולהמשיך לערוך אותו. |
לעתים, אי אפשר לדעת בזמן כתיבת הקוד את כמות הזיכרון הנדרשת לצורך הריצה. מערכת ניהול הזיכרון הדינאמי מאפשרת להקצות ולשחרר זיכרון בזמן הריצה.
|
|
כדאי לדעת: קטעי הקוד שבפרק זה משתמשים בספרייה הסטנדרטית. נדון בספריות באופן מעמיק יותר כאן. לעת עתה, פשוט יש לזכור לרשום בראשי הקבצים המשתמשים בקטעי הקוד שבפרק זה#include <stdlib.h> |
הצורך בניהול זיכרון דינאמי[]
במערכים ראינו תוכנית לקליטת מספרים והדפסתם בסדר הפוך:
#include <stdio.h>
int main()
{
int numbers[10];
int i;
for(i = 0; i < 10; i++)
scanf("%d",&numbers[i]);
for(i = 9; i >= 0; i--)
printf("%d\n",numbers[i]);
return 0;
}התוכנית יודעת לטפל ב-10 מספרים בדיוק.
כעת נחשוב על מקרה שונה. המשתמש אינו יודע כלל מראש כמה מספרים ברצונו להקליד. נכתוב, לכן, תוכנית, ששואלת אותו לאחר כל מספר, האם הוא רוצה להמשיך או לא:
#include <stdio.h>
int main()
{
int c;
int numbers[10];
int i;
do
{
int d;
printf("Please enter a number: ");
scanf("%d", &d);
numbers[i] = d;
printf("Please enter 0 to quit, or any other number to continue: ");
scanf("%d", &c);
}
while(c != 0);
printf("The numbers you entered, in reverse order, are:\n");
while(i > 0)
printf("%d\n",numbers[i--]);
return 0;
}נשים לב שתוכנית זו פועלת עד 10 מספרים. אם המשתמש יקליד יותר מספרים מכך, נקבל גלישה מהמערך. לכאורה, קל לתקן זאת. נחליף את השורה:
int numbers[10];בשורה:
int numbers[1000];אך ברור למדי שה"פתרון" בעייתי:
- לא פתרנו את הבעיה, אלא "דחינו" אותה, מ-10 ל-1000.
- אם יתברר בדיעבד שהמשתמש הקליד 9 מספרים, חבל שהקצינו מערך כה גדול.
מערכת ניהול הזיכרון הדינאמי[]
כפי שראינו במצביעים, אפשר לחשוב על זיכרון המחשב כמערך ארוך. חלק ממערך זה, הערימה (heap בלעז), מיועד למערכת ניהול הזיכרון הדינאמי. נוכל לדמיין את הערימה בתחילה כריקה כולה, כך:
{kind=link}
במהלך ריצת התוכנית, נוכל להשתמש בפונקציות כדי לבקש ממערכת ההפעלה להקצות לנו זיכרון (רציף) בגודל המבוקש. מערכת ההפעלה תחפש האם קיים קטע זיכרון מתאים בערימה, ואם כן, תסמן אותו כתחת שימוש ותחזיר לנו את כתובתו. לדוגמה, אם נבקש 6 בתים, הערימה תוכל להראות כך:
{kind=link}
ששת הבתים הללו מסומנים כתחת שימוש. אם תגיע עוד בקשה להקצאת זיכרון, מערכת ההפעלה לא תחזיר כתובת של קטע החופף לקטע הזה. במילים אחרות, קטע זה בטוח לשימושנו. לאחר שנסיים להשתמש בקטע הזיכרון, נוכל להשתמש בפונקציה אחרת כדי לשחרר אותו. הדבר יודיע למערכת ההפעלה שקטע זה אינו בשימוש יותר, ואפשר להקצותו לבקשות אחרות.
|
|
כדאי לדעת: מערכת ההקצאה הדינמית משתמשת באיזור הזיכרון heap, ואילו משתנים מקומיים נשמרים באיזור הזיכרון stack. |
הקצאה[]
גודל ההקצאה הרצוי[]
כדי להקצות זיכרון, צריך לדעת ראשית את גודל הזיכרון הרצוי (בבתים). לרוב אנו יודעים משהו שונה במקצת: טיפוס המשתנים הרצוי, ומספר המשתנים הרצויים ברצף.
שפת C מאפשרת לנו לתרגם דרישות טיפוסים וסוגים לדרישות גודל על ידי המילה השמורה sizeof. כדי לראות את מספר הבתים שתופס טיפוס, נשתמש באופרטור sizeof בצורה:
sizeof(<t>)כאשר t הוא טיפוס או משתנה. לדוגמה:
sizeof(int)הוא מספר הבתים שתופס משתנה מסוג שלם, ואילו:
sizeof(char) * 80הוא מספר הבתים שתופסים 80 תווים רצופים (כמו במערך של תווים, לדוגמה). חשוב להשתמש במילה השמורה sizeof ולא להסתמך על כך שהגודל אותו תופס טיפוס מסויים כבר ידוע (למשל - 4 עבור משתנה מטיפוס שלם). הסיבה היא שבמחשבים מארכיטקטורות שונות ייתכן מצב בו משתנה מאותו טיפוס יתפוס נפח זיכרון שונה.
פונקציות ההקצאה malloc וcalloc[]
כדי להקצות זיכרון, אפשר להשתמש בפונקציה malloc, בקריאה מהצורה הבאה:
malloc(<total_size>)כאשר total_size הוא הגודל (בבתים) שאותו רוצים להקצות. לדוגמה:
malloc(sizeof(int))היא בקשה להקצות מספיק בתים לשלם יחיד, ואילו:
malloc(sizeof(int) * 80)היא בקשה להקצות מספיק בתים ל-80 שלמים רצופים.
לחלופין, אפשר להשתמש בפונקציה calloc, בקריאה מהצורה הבאה:
calloc(<num>, <size>)כאשר num * size הוא הגודל (בבתים) שאותו רוצים להקצות. בפרט, אם num הוא מספר משתנים, וsize הוא גודל כל אחד מהם, אז הקריאה הנ"ל תקצה מקום רציף לnum משתנים. לדוגמה:
calloc(80, sizeof(int));היא בקשה להקצות מספיק בתים ל80 שלמים רצופים.
שתי הפונקציות נבדלות בעיקר בכך שcalloc, מעבר להקצאת זיכרון, גם מאפסת את קטע הזיכרון אותו היא מקצה. למעט זאת, אין הבדל בין הקריאות הבאות:
malloc(80 * sizeof(int));
calloc(80, sizeof(int));
calloc(sizeof(int), 80);הערך המוחזר[]
הן malloc והן calloc מחזירות את כתובת הזיכרון שאותו היקצו. טיפוס הערך המוחזר הוא void * (שהוסבר כאן). אם הפונקציות נכשלו בהקצאה, הכתובת שיחזירו תהיה NULL. לרוב, לכן, יש שתי פעולות שיש לבצע על הערך המוחזר:
- להשים אותו למשתנה מצביע.
- לבדוק האם הערך המוחזר הוא NULL, ובמקרה שכן, לטפל בכישלון ההקצאה.
מיד נראה דוגמה כיצד לעשות שתי פעולות אלו.
דוגמה[]
להלן קטע קוד טיפוסי המקצה מקום למערך של n שלמים:
int *numbers = (int *)malloc( n * sizeof(int) );
if(numbers == NULL)
printf("Error: could not allocate memory!\n");נעבור כעת על חלקי הקוד. הקריאה
malloc( n * sizeof(int) )קוראת לפונקציה malloc, ומבקשת להקצות מקום לn מספרים שלמים. קריאה זו מחזירה טיפוס void *. את תוצאת הקריאה רוצים להשים בnumbers שהוא מטיפוס int *. ההסבה (cast בלעז)
(int *)מבקשת מהמהדר להתייחס לטיפוס המוחזר כמצביע לשלמים ולא כvoid *. השורה
int *numbers = (int *)malloc( n * sizeof(int) );}}משימה לכן למצביע numbers את תוצאות ההקצאה המבוקשת. השורה
if(numbers == NULL)בודקת האם ההקצאה נכשלה, והשורה לאחריה מדפיסה הודעה בהתאם.
שפת C ידועה בקיצורים הרבים שהיא מאפשרת. יש הכותבים את שורת הבדיקה כך:
if(!numbers)נזכר שהקבוע NULL הנו למעשה 0, וכל מה שאינו 0 הנו ערך אמת בוליאני בשפת C. עם זאת, למען קריאות הקוד - עדיף להשתמש בצורה המלאה של שורת הבדיקה.
שחרור[]
פונקצית השחרור free[]
כדי לשחרר זיכרון שהוקצה, משתמשים בפונקציה free לפי הצורה:
free(<p>)כאשר p היא כתובת זיכרון שהוחזרה על ידי אחת מפונקציות ההקצאה. אסור להעביר לפונקציה free כתובת זיכרון אחרת, או כתובת זיכרון שכבר שוחררה (אלא אם כן היא הוקצתה מאז מחדש, כמובן).
הנה דוגמה לשימוש בfree:
int *numbers = (int *)malloc(sizeof(int) * 80);
...
free(numbers);להלן מספר שימושים שגויים בfree:
int n;
free(&n) /* This is not the address of allocated memory! */וכן:
int *numbers = (int *)malloc(sizeof(int) * 80);
...
free(numbers);
free(numbers); /* This second deallocation is a mistake! */חשיבות השחרור[]
כפי שראינו במערכת ניהול הזיכרון הדינאמי, קטע זיכרון שלא נשחרר אותו במפורש - לא יהיה זמין יותר לשימוש - זיכרון המחשב הוא משאב מוגבל.
|
|
שימו לב: הקצאה דינאמית של זיכרון מבלי לשחררו - דליפת זיכרון (memory leak בלעז) - עלולה לפגוע בביצועי המערכת. |
מערכות הפעלה מודרניות יודעות להתמודד עם דליפת זיכרון של תוכנית, ולאחר שהיא מסיימת את פעילותה - לפנות את הזיכרון שהקצתה. עם זאת, כל זה מסייע רק כאשר כותבים יישום שאמור לבצע פעולה קצרה ותו לא. יישום שפועל באופן רציף (למשל - משחק מחשב) וסובל מדליפת זיכרון, אפילו מצומצמת מאוד, יאט את פעילות המחשב עד שבסופו של דבר יקרוס.
דוגמה: רשימה מקושרת[]
נפתור כאן את הבעיה שראינו בהצורך בניהול זיכרון דינאמי, על ידי רשימה מקושרת.
מהי רשימה מקושרת?[]
רשימה מקושרת היא מבנה נתונים המורכב מחוליות. כל חוליה היא מבנה ששדותיו הם תוכן החוליה (לדוגמה מספר שלם) ומצביע לחוליה הבאה. התרשים הבא מראה זאת.
{kind=link}
נממש חוליה על ידי הstruct הבא:
struct link_
{
int data;
struct link_ *next;
};
typedef struct link_ link;במבנה זה, השדה data מכיל את תוכן החוליה, והשדה next הוא מצביע לחוליה הבאה.
{kind=link}
כפי שהראה התרשים הראשון, נחזיק מספר חוליות כאלו. כל אחת מהן תצביע לבאה. בנוסף, נחזיק מצביע head, שיצביע לחוליה הראשונה ברשימה.
הוספת חוליה[]
נניח שמשתנה d מכיל ערך כלשהו, ואנו מעוניינים ליצור חוליה חדשה המכילה ערך זה, ולהוסיף חוליה זו לראש הרשימה.
ראשית מקצים זיכרון לחוליה חדשה, ומשימים את התוצאה למצביע l (כמובן שבודקים האם ההקצאה הצליחה):
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
/* Handle allocation failure. */
...{kind=link}
כעת קובעים שערך data, התוכן, הוא d, וערך next, המצביע לחוליה הבאה, לhead, ראש הרשימה:
l->data = d;
l->next = list->head;{kind=link}
לבסוף קובעים שראש הרשימה הוא l:
head = l;{kind=link}
קטע הקוד הבא מסכם זאת:
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
/* Handle allocation failure. */
...
l->data = d;
l->next = list->head;
head = l;מחיקת חוליה[]
נניח שאנו רוצים לשמור את תוכן החוליה הראשונה במשתנה d, ולמחוק את החוליה הראשונה.
שתי השורות הבאות מאתחלות מצביע l לחוליית הראש ומשתנה d לתוכנו:
link *const l = list->head;
const int d = l->data;{kind=link}
כעת נגרום למצביע לראש הרשימה להצביע על החוליה הבאה:
head = l->next;{kind=link}
לבסוף, נשחרר את החוליה המיותרת:
free(l);{kind=link}
קטע הקוד הבא מסכם זאת:
link *const l = list->head;
const int d = l->data;
head = l->next;
free(l);שימוש לקליטת והפיכת מספרים[]
נוכל להשתמש ברשימה מקושרת לצורך קליטת מספרים והדפסתם בסדר הפוך. הפתרון שנראה כאן מדגיש את הנקודות החדשות הנוגעות לניהול זיכרון דינאמי, ונכתוב אותו בצורה רשלנית מבחינת הנדסת תוכנה; במעט על מבנים והנדסת תוכנה נתקן זאת מעט. להלן התוכנית:
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main()
{
do
{
int d;
printf("Please enter a number: ");
scanf("%d", &d);
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
return -1;
l->data = d;
l->next = list->head;
head = l;
printf("Please enter 0 to quit, or any other number to continue: ");
scanf("%d", &c);
}
while(c != 0);
printf("The numbers you entered, in reverse order, are:\n");
while(list_size(&lst) > 0)
{
link *const l = list->head;
const int d = l->data;
head = l->next;
free(l);
printf("%d\n", d);
}
return 0;
}
הקוד מורכב משני חלקים עיקריים.
החלק הראשון מורכב מלולאת לולאת do while. הוא מבקש מספר מהמשתמש, מכניס מספר לרשימה המקושרת כפי שראינו בהוספת חוליה, ושואל האם יש עוד מספרים להוסיף:
do
{
int d;
printf("Please enter a number: ");
scanf("%d", &d);
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
return -1;
l->data = d;
l->next = list->head;
head = l;
printf("Please enter 0 to quit, or any other number to continue: ");
scanf("%d", &c);
}
while(c != 0);החלק השני עובד בלולאת while. הוא מוצא את הערך בראש הרשימה, מוחק את החוליה בראש הרשימה כפי שראינו במחיקת חוליה, ומדפיס את הערך.
printf("The numbers you entered, in reverse order, are:\n");
while(list_size(&lst) > 0)
{
link *const l = list->head;
const int d = l->data;
head = l->next;
free(l);
printf("%d\n", d);
}שינוי הקצאה[]
|
|
שקול לדלג על נושא זה הבנה שטחית של נושא זה עלולה ליצור קטעי קוד בעלי דליפת זיכרון פוטנציאלית. מומלץ לחזור לנושא לאחר שליטה סבירה בניהול זיכרון דינאמי. |
הבעיה[]
לפעמים נתקלים בבעיה הבאה. המצביע p מצביע לרצף זיכרון מוקצא בעל מספר בתים כלשהו, אך פתאום נוכחים לדעת שיש צורך להגדיל או להקטין את רצף הזכרון המוקצה. לדוגמה, נתבונן בקטע הקוד הבא:
char *chars = (char *)calloc(3, sizeof(char));
if(!chars)
...
chars[0] = 'a';
chars[1] = 'b';
chars[1] = 'e';
/* Do some operations. */
...בתחילה מקצים לchars רצף המתאים למערך של 3 תווים, אך לאחר רצף פעולות כלשהו, יש צורך להגדיל את הרצף המוצבע על ידי chars למערך של 5 תווים, לדוגמה.
פונקציית שינוי-ההקצאה realloc[]
שינויי הקצאות אפשר לעשות בעזרת הפונקציה realloc, על ידי קריאות מהצורה הבאה:
realloc(<old_ptr>, <total_size>)כאשר old_ptr הוא כתובת הזיכרון המוקצא הנוכחי, וtotal_size הוא הגודל החדש המבוקש (בבתים).
מערכת ההפעלה תנסה לראות האם אפשר לשנות את רצף הזיכרון הנוכחי לגודל המבוקש. אם הדבר אפשרי, הפונקציה תחזיר את כתובת הזיכרון של הרצף הנוכחי כvoid * (בדיוק כפי שראינו מקודם בהקצאה). אם הדבר אינו אפשרי, היא תבדוק האם יש רצף אחר מתאים בזיכרון. אם היא הצליחה, היא תעתיק את תוכן הרצף הנוכחי לרצף החדש, תשחרר את הרצף הנוכחי, ותחזיר את כתובת הרצף החדש. אם אין רצף אחר מתאים בזיכרון, היא לא תשנה כלום בזיכרון (ובפרט, לא תשחרר את הרצף הנוכחי), ותחזיר NULL כדי לסמן שלא הצליחה.
שני התרשימים הבאים מראים מצב אפשרי בו realloc תחזיר כתובת זיכרון שונה מהכתובת הנוכחי. תחילה נראה הזיכרון כך:
{kind=link}
שני רצפים נמצאים כעת בזיכרון: אחד מתאים למצביע chars, והשני למצביע אחר py. אפשר להאריך את רצף הזיכרון הנוכחי של chars בתו אחד, אך לא בשניים. הפונקציה realloc תזהה שקיים רצף אחר גדול מספיק, תקצה אותו, תעתיק את שלושת התווים אליו, תשחרר את הרצף הנוכחי, ותחזיר את הכתובת החדשה. לאחר שנשים את הכתובת החדשה בchars, ייראה הזיכרון כך:
{kind=link}
מעט על מבנים והנדסת תוכנה[]
הבעיה[]
בשימוש ברשימה מקושרת לקליטת והפיכת מספרים ראינו כיצד להשתמש ברשימה מקושרת כדי לקלוט מספרים ולהדפיסם בסדר הפוך. הפתרון שראינו, למרות נכונותו - בעייתי. קשה לכתוב ולתחזק קוד כזה (ראה גם מעט על פונקציות והנדסת תוכנה). בפרט, הקוד שמטפל בקלט ופלט מעורבב בקוד שמנהל את הרשימה המקושרת. לכן:
- קשה לעשות שימוש חוזר (כלומר בתוכנית אחרת) בקוד הרשימה המקושרת
- הקוד מסובך להבנה יחסית למה שהוא עושה
- אם תתגלה שגיאה בקוד, יהיה קשה יותר להבין איזה חלק גרם לה
כימוס מחסנית[]
struct list_
{
link *head;
unsigned long size;
};
typedef struct list_ list;
void list_ctor(list *list);
void list_dtor(list *list);
unsigned long list_size(const list *list);
int list_push(list *list, int data);
int list_pop(list *list);
int list_head(const list *list);
void list_ctor(list *list)
{
list->head = NULL;
list->size = 0;
}
void list_dtor(list *list)
{
link *l = list->head;
while(l != NULL)
{
link *const old = l;
l = old->next;
free(old);
}
list_ctor(list);
}
unsigned long list_size(const list *list)
{
return list->size;
}
int list_push(list *list, int data)
{
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
return -1;
l->data = data;
l->next = list->head;
list->head = l;
++list->size;
return 0;
}int list_pop(list *list)
{
link *const l = list->head;
const int data = l->data;
list->head = l->next;
--list->size;
free(l);
return data;
}
int list_head(const list *list)
{
const link *const l = list->head;
return l->data;
}מעט על מבנים והנדסת תוכנה[]
הבעיה[]
בשימוש ברשימה מקושרת לקליטת והפיכת מספרים ראינו כיצד להשתמש ברשימה מקושרת כדי לקלוט מספרים ולהדפיסם בסדר הפוך. הפתרון שראינו, למרות נכונותו - בעייתי. קשה לכתוב ולתחזק קוד כזה (ראה גם מעט על פונקציות והנדסת תוכנה). בפרט, הקוד שמטפל בקלט ופלט מעורבב בקוד שמנהל את הרשימה המקושרת. לכן:
- קשה לעשות שימוש חוזר (כלומר בתוכנית אחרת) בקוד הרשימה המקושרת
- הקוד מסובך להבנה יחסית למה שהוא עושה
- אם תתגלה שגיאה בקוד, יהיה קשה יותר להבין איזה חלק גרם לה
כימוס רשימה[]
נחשוב ראשית מה הפעולות שבהן היינו רוצים שרשימה תתמוך. להלן הצעה אפשרית:
- פעולה שיוצרת רשימה
- פעולה שהורסת רשימה בתום השימוש (כולל שחרור משאבים שטרם שוחררו)
- שאילתה לגבי מספר האיברים
- דחיפת איבר לראש הרשימה
- שליפת איבר מראש הרשימה
- שאילתה לגבי האיבר בראש הרשימה
כדי לתמוך בפעולות הנ"ל, אפשר לממש רשימה כמבנה ששדותיו הם מצביע לראש הרשימה ומונה למספר האיברים ברשימה:
struct list_
{
link *head;
unsigned long size;
};
typedef struct list_ list;להלן ההצהרות לפעולות שבהן רצינו שרשימה תתמוך:
/* Constructs a list (prepares it for use). */
void list_ctor(list *list);
/* Destructs a list (after use). */
void list_dtor(list *list);
/* Returns the number of elements in the list. */
unsigned long list_size(const list *list);
/* Pushes new data to the head of the list.
* Returns 0 if the operation succeeded, -1 otherwise. */
int list_push(list *list, int data);
/* Pops (removes) the element at the head of the list.
* Returns the element.
* Don't call if the size of the list is 0. */
int list_pop(list *list);
/* Returns the element at the head of the list.
* Don't call if the size of the list is 0. */
int list_head(const list *list);כעת נוכל לממש כל אחת מפעולות אלו.
void list_ctor(list *list)
{
list->head = NULL;
list->size = 0;
}
void list_dtor(list *list)
{
link *l = list->head;
while(l != NULL)
{
link *const old = l;
l = old->next;
free(old);
}
list_ctor(list);
}
unsigned long list_size(const list *list)
{
return list->size;
}
int list_push(list *list, int data)
{
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
return -1;
l->data = data;
l->next = list->head;
list->head = l;
++list->size;
return 0;
}int list_pop(list *list)
{
link *const l = list->head;
const int data = l->data;
list->head = l->next;
--list->size;
free(l);
return data;
}
int list_head(const list *list)
{
const link *const l = list->head;
return l->data;
}שימוש ברשימה המכומסת[]
כעת, לאחר שכימסנו את הרשימה, נוכל להשתמש בה כדי לקלוט מספרים ולהדפיסם בסדר הפוך:
int main()
{
int c;
list lst;
list_ctor(&lst);
do
{
int d;
printf("Please enter a number: ");
scanf("%d", &d);
list_push(&lst, d);
printf("Please enter 0 to quit, or any other number to continue: ");
scanf("%d", &c);
}
while(c != 0);
printf("The numbers you entered, in reverse order, are:\n");
while(list_size(&lst) > 0)
printf("%d\n", list_pop(&lst));
list_dtor(&lst);
return 0;
}נשים לב שהקוד מופרד הרבה יותר. הקוד בmain עוסק כמעט כולו בבירור בקליטת המספרים והדפסתם. הקוד המטפל בחוליות נמצא במקום אחר לחלוטין. בדוגמה לרשימות מקושרות במודולים נראה אפילו כיצד להפריד את הקוד לקבצים שונים לצורך שימוש חוזר.
להלן הקוד המלא בשלב זה:
#include <stdio.h>
#include <stddef.h>
#include <malloc.h>
struct link_
{
struct link_ *next;
int data;
};
typedef struct link_ link;
struct list_
{
link *head;
unsigned long size;
};
typedef struct list_ list;
/* Constructs a list (prepares it for use). */
void list_ctor(list *list);
/* Destructs a list (after use). */
void list_dtor(list *list);
/* Returns the number of elements in the list. */
unsigned long list_size(const list *list);
/* Pushes new data to the head of the list.
* Returns 0 if the operation succeeded, -1 otherwise. */
int list_push(list *list, int data);
/* Pops (removes) the element at the head of the list.
* Returns the element.
* Don't call if the size of the list is 0. */
int list_pop(list *list);
/* Returns the element at the head of the list.
* Don't call if the size of the list is 0. */
int list_head(const list *list);
void list_ctor(list *list)
{
list->head = NULL;
list->size = 0;
}
void list_dtor(list *list)
{
link *l = list->head;
while(l != NULL)
{
link *const old = l;
l = old->next;
free(old);
}
list_ctor(list);
}
unsigned long list_size(const list *list)
{
return list->size;
}
int list_push(list *list, int data)
{
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
return -1;
l->data = data;
l->next = list->head;
list->head = l;
++list->size;
return 0;
}
int list_pop(list *list)
{
link *const l = list->head;
const int data = l->data;
list->head = l->next;
--list->size;
free(l);
return data;
}
int list_head(const list *list)
{
const link *const l = list->head;
return l->data;
}
int main()
{
int c;
list lst;
list_ctor(&lst);
do
{
int d;
printf("Please enter a number: ");
scanf("%d", &d);
list_push(&lst, d);
printf("Please enter 0 to quit, or any other number to continue: ");
scanf("%d", &c);
}
while(c != 0);
printf("The numbers you entered, in reverse order, are:\n");
while(list_size(&lst) > 0)
printf("%d\n", list_pop(&lst));
list_dtor(&lst);
return 0;
}
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
איגודים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C איגוד (union בלעז) הוא מבנה שיש חפיפה בין מיקום שדותיו בזיכרון. הוא משמש בעיקר לחיסכון במקום, או להסבות שיכולות לעקוף את מנגנון הטיפוסים של השפה.
|
|
שקול לדלג על נושא זה איגודים הם מבנים בעייתיים מבחינת הנדסת תוכנה, ומועדים לפורענות בשגיאות קוד. הם תוכננו בימים בהם זיכרון המחשב היה מוגבל ביותר, ומהווים בעיקר טכניקה קיצונית לחיסכון בזיכרון במקרים מסויימים, או להסבות קיצוניות בין טיפוסים שונים. מומלץ שתחזור לנושא זה אם אתה נתקל בהם בספרייה כלשהי. |
מהו איגוד?[]
איגוד, כמבנה, הוא טיפוס חדש, שאנו מגדירים את שמו ומרכיביו כרצוננו. לאיגוד, כלמבנה, יש שדות, שהם איברים בעלי טיפוסים ושמות שאנו בוחרים. כפי שמגדירים מבנה בעזרת המילה השמורה struct, כך מגדירים איגוד בעזרת המילה השמורה union. איגוד נבדל ממבנה בנקודה מהותית יחידה: בכל נקודת זמן במהלך הריצה, מבנה מאפשר גישה לכל אחד מהשדות שהוגדרו בו, ואיגוד מאפשר גישה לשדה יחיד מהשדות שהוגדרו בו. לאחר שמבינים נקודה זו, רוב הנקודות (לדוגמה, איך מגדירים איגוד, או שימוש בtypedef) דומות לאלה שבמבנים.
לדוגמה, נניח שאנו צריכים בכל נקודת זמן בתכנית מספר שלם או מחרוזת בגודל 20. נוכל לבנות טיפוס חדש שיתאר זאת, ולהשתמש בטיפוסים מסוגו.
דוגמה לשימוש באיגוד[]
להלן תוכנית קצרה המשתמשת באיגוד:
#include <stdio.h>
#include <string.h>
union foo
{
int a_number;
char a_string[20];
};
int main()
{
union foo f;
f.a_number = 3;
printf("%d\n", f.a_number);
strcpy(f.a_string, "hello");
printf("%s\n", f.a_string);
return 0;
}
ראשית, מגדירים טיפוס חדש, foo:
union foo
{
int a_number;
char a_string[20];
};הטיפוס יכול להכיל בכל יחידת זמן, מספר a_number, או מחרוזת a_string.
בתוך הפונקציה main, מגדירים משתנה מטיפוס foo:
union foo f;כעת הגענו לחלק מהתוכנית בו רוצים להשתמש בשדה a_number. אפשר לגשת אליו כמו לשדהו של מבנה:
f.a_number = 3;
printf("%d\n", f.a_number);כעת הגענו לחלק מהתוכנית בו רוצים להשתמש בשדה a_string. שוב, אפשר לגשת אליו כמו לשדהו של מבנה:
strcpy(f.a_string, "hello");
printf("%s\n", f.a_string);איגודים וזיכרון המחשב[]
נתבונן בקטע הקוד הבא:
union foo
{
short int c;
int m;
};כיצד ייראה עצם מסוג union foo בזיכרון? כעת נעבור על כך. ההשוואה עם מבנים וזיכרון המחשב תעזור לנו להבין את הצדדים המיוחדים לאיגודים. union foo דומה למבנה שלו שני שדות, אלה ששני שדות אלה נמצאים באותו המקום בזיכרון:

כלומר, שני השדות חופפים בזיכרון, וערכיהם דורסים זה את זה:

הסכנה באיגודים[]
התרשימים באיגודים וזיכרון המחשב עוזרים להסביר את הסיכונים שבשימוש באיגודים: שדות האיגוד חופפים זה לזה בזיכרון, ולכן שינוי אחד מהם "מזבל" את האחרים. כך, לדוגמה, נתבונן בקוד הבא:
strcpy(f.a_string, "hello");
printf("%d\n", f.a_number);השורה הראשונה מעתיקה מחרוזת לשדה a_string של f, והשורה הבאה משתמשת בערך השדה a_number של a. מהו ערך זה? השורה הראשונה דרסה כל ערך קודם שהיה במשתנה, והוא מכיל כעת זבל.
איגודים כשדות מבנים[]
איגודים, ככל טיפוס אחר, יכולים להיות טיפוסי השדות של מבנים. כך, לדוגמה, בקוד הבא:
union a
{
int b;
char c;
};
struct d
{
float f;
union a e;
};e הוא שדה של struct d, וטיפוסו הוא union a.
כפי שאפשר לראות בסכנה באיגודים, הסכנה בשימוש באיגוד היא שהאיגוד עצמו אינו מציין מי השדה שבשימוש כרגע. פתרון הגיוני לבעיה זו היא להשתמש בשני משתנים: משתנה אחד מטיפוס האיגוד, ומשתנה נוסף שיתאר מי משדות האיגוד כרגע בשימוש. היות ששני המשתנים הללו קשורים ביניהם, הגיוני לקשור אותם במבנה:
union foo
{
int a_number;
char a_string[20];
};
struct foo
{
int is_number;
union foo f;
};השדה is_number מתאר האם השדה f מכיל כרגע מספר או מחרוזת.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
פלט וקלט קבצים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C בפרק פלט וקלט ראינו כיצד לפלוט ולקלוט מידע מהמשתמש ישירות. בפרק זה נראה כיצד לפלוט ולקלוט מידע מקבצים.
|
|
כדאי לדעת: קטעי הקוד שבפרק זה משתמשים בספרייה הסטנדרטית. נדון בספריות באופן מעמיק יותר כאן. לעת עתה, פשוט יש לזכור לרשום בראשי הקבצים המשתמשים בקטעי הקוד שבפרק זה#include <stdio.h> |
תו סיום-הקובץ EOF[]
במחרוזות ותו האפס, ראינו שיש מוסכמה לפיה תו האפס מסיים את חלק המחרוזת המכיל תוכן אמיתי (גם אם המערך ארוך יותר). באופן דומה, ישנו תו מיוחד, EOF, המסמן לפי מוסכמה את סיום התוכן האמיתי של קובץ.
המבנה FILE והעבודה אתו[]
המבנה FILE מוגדר בקובץ הכותרת file.h, והוא משמש לכל פונקציות הפלט והקלט שנראה בפרק זה. כמו לכל מבנה אחר, גם למבנה FILE יש שדות, אולם כלל לא נאזכר כאן מהם שדותיו ומשמעותם, שכן המבנה לא תוכנן כך שייגשו ישירות לשדותיו. צורת העבודה עם מבנה זה היא כזו:
- משתמשים בפונקציית ספריה כדי לקבל מצביע למבנה זה. נראה זאת בפתיחת קובץ.
- משתמשים בפונקציות הספריה כדי לבצע פעולות שונות בקובץ. אחד הארגומנטים שמקבלת כל פונקציה היא מצביע לFILE, ומעבירים לפונקציה את המצביע שקבלנו.
- בסיום השימוש בקובץ, משתמשים בפונקציית ספרייה כדי להודיע שסיימנו להשתמש בו, וגם כאן מעבירים לפונקציה את המצביע שקיבלנו. נראה זאת בסגירת קובץ.
פתיחת קובץ[]
הקריאה לfopen והערך המוחזר[]
פתיחת קובץ מתבצעת על ידי קריאה לfopen, המחזיר מצביע לFILE. אם המצביע הנו NULL, פתיחת הקובץ נכשלה. לכן תמיד יש לבדוק את הערך המוחזר מפונקציה זו (הדבר דומה להקצאת זיכרון במידה מסויימת).
כדי לפתוח את הקובץ "try.txt", לדוגמה, אפשר לבצע זאת:
FILE *f = fopen("try.txt" , "rt");
if(!f)
{
/* Handle case where couldn't open file. */
}השורה הראשונה פותחת את הקובץ על ידי fopen, ומשימה את המצביע המוחזר למצביע f. הארגומנט הראשון שמקבלת הפונקציה הוא שם הקובץ (אם אינו בתיקית התוכנית, בנתיב מלא או יחסי אליו); הארגומנט השני הוא מחרוזת סוג הפתיחה, שעליה נדבר מיד, והיא כאן מבקשת לפתוח לקריאה קובץ טקסט (מלל). השורה הבאה בודקת למעשה אם f קיבל את הערך NULL. אם כן, פתיחת הקובץ נכשלה, ויש לטפל בכך.
מחרוזת סוג הפתיחה[]
בדוגמה שראינו זה עתה, מחרוזת סוג הפתיחה "rt" מבקשת לפתוח לקריאה קובץ טקסט (מלל): "r" מסמנת את מוד הפתיחה, המציינת מה רוצים לעשות עם הקובץ, ו"t" מסמנת את תוכן הקובץ. תמיד יוצרים את מחרוזת סוג הפתיחה על ידי בחירה של אחת מהאפשרויות בטבלה מוד הפתיחה שלאחריה בחירה של אחת מהאפשרויות בטבלה תוכן הקובץ.
| תווים | משמעות |
|---|---|
| r | פתיחת קובץ קיים לקריאה. אם לא קיים קובץ בשם האמור, הפתיחה תכשל. |
| w | פתיחת קובץ חדש לכתיבה. אם קיים כבר קובץ בשם האמור, תוכנו ימחק. |
| a | פתיחת קובץ קיים לכתיבת נתונים בסופו. התוכן החדש ידרוס את תו ה-EOF, וייכתב אחריו. אם הקובץ לא קיים, הוא יווצר תחילה. |
| r+ | פתיחת קובץ קיים לקריאה וכתיבה. אם לא קיים קובץ בשם האמור, הפתיחה תכשל. |
| w+ | פתיחת קובץ חדש לקריאה וכתיבה. אם קיים כבר קובץ בשם האמור, תוכנו ימחק. |
| a+ | פתיחת קובץ קיים לכתיבת נתונים בסופו. תו סיום הקובץ יוזז לסוף הנתונים החדשים שנכתוב, כך שבהצגת תוכן הקובץ, יוצג כל התוכן. אם הקובץ לא קיים, הוא יווצר תחילה. |
| תווים | משמעות |
|---|---|
| t | קובץ טקסט |
| b | קובץ בינרי |
סגירת קובץ[]
בסיום עבודה עם קובץ פתוח, יש לסגור אותו. הדבר דומה לשחרור זיכרון במידה מסויימת.
הפונקציה fclose[]
הפונקציה fclose סוגרת קובץ שנפתח על ידי fopen. משתמשים בה בצורה:
fclose(<f>);כאשר f הוא מצביע לFILE שהוחזר מקריאה מוצלחת מfopen.
חשיבות סגירת קבצים[]
קבצים פתוחים הם אחד ממשאבי מערכת ההפעלה, ולכן עדיף להמנע מלנהוג בהם בבזבוז. בפרט, יש לסגור כל קובץ שאותו פתחנו.
|
|
שימו לב: ריבוי קבצים פתוחים עלול לפגוע בביצועי המערכת. |
פלט[]
הפונקציה fprintf[]
הפונקציה fprintf דומה מאד לפונקציה printf (שכבר ראינו בפלט וקלט):
fprintf(f, "This line will be written to the file.\n");
יש לשים לב לשינויים הבאים:
- הארגומנט הראשון הוא מצביע לFILE.
- הפונקציה מדפיסה לקובץ שאותו מתאר הFILE.
- רצוי לבדוק את הערך המוחזר מהפונקציה, שכן כתיבה לקובץ עלולה להיכשל.
הפונקציה מחזירה מספר שלילי במקרה כישלון פלט. להלן דוגמה לבדיקה:
if( fprintf("Hello world") < 0)
... /* Handle error. */להלן דוגמה לשימוש בfprintf:
#include <stdio.h>
int main()
{
FILE *const f = fopen("new_file.txt", "wt");
if(!f)
{
printf("Error: could not open file!\n");
return -1;
}
fprintf(f, "This line will be written to the file.\n");
fprintf(f, "Here is another line: %d + %d = %d", 2, 2, 2 + 2);
fclose(f);
return 0;
}השורות:
FILE *const f = fopen("new_file.txt", "wt");
if( !f )
{
printf("Error: could not open file!\n");
return -1;
}מייצרות קובץ בשם "new_file.txt", ופותחות אותו לכתיבה כקובץ טקסט, בודקות האם הפעולה הצליחה, ומטפלות במצב אם לא.
השורות:
fprintf(f, "This line will be written to the file.\n");
fprintf(f, "Here is another line: %d + %d = %d", 2, 2, 2 + 2);מראות קריאות דומות לאלה שהיינו עושים כדי להדפיס בעזרת printf, אלא שאנו משתמשים בfprintf, והארגומנט הראשון הוא המצביע לFILE.
השורות:
fclose(f);
return 0;
}סוגרות את הקובץ, ומודיעות למערכת ההפעלה שהתוכנית הצליחה.
אם נריץ את התוכנית, נוכל לראות שאכן נוצר קובץ בשם המבוקש, ומופיעה בו השורה שכתבנו.
עוד פונקציות[]
הספריה הסטנדרטית כוללת עוד פונקציות פלט לקבצים, לדוגמה fputs וfwrite.
קלט[]
הפונקציה fscanf[]
הפונקציה fscanf דומה מאד לפונקציה scanf (שכבר ראינו בפלט וקלט):
fscanf(f, "%d", &count);יש לשים לב למעט השינויים הבאים:
- הארגומנט הראשון הוא מצביע לFILE.
- הפונקציה קולטת מהקובץ שאותו מתאר הFILE.
- חשוב במיוחד לבדוק את הערכים המוחזרים מהקריאות, מפני שאין להניח את הצלחתן של קריאות מקובץ.
נניח שfscanf ביקשה לקרוא ל משתנים. אז הקריאה מוצלחת אם הפונקציה מחזירה n. להלן דוגמה לבדיקה:
int d;
char c;
if( fscanf("%d %c", &d, &c) != 2)
... /* Handle error. */
|
|
שימו לב: התעלמות מהערך המוחזר מקריאות לfscanf תוביל לתוצאות לא מוגדרות אם תוכן הקובץ אינו תואם את מה שהתוכנית מצפה לו. |
הפונקציה fgets[]
הפונקציה fgets מאפשרת לקלוט מחרוזת מקובץ לתוך מערך תווים, כפי שראינו בקלט מחרוזות. לדוגמה:
char a[50];
fgets(a, 49, f);הקריאה:
fgets(a, 49, stdin);תקלוט עד 49 תווים מתוך קובץ. אם ב49 התווים הראשונים יש מעבר לשורה חדשה (על ידי Enter), ייקלטו רק התווים עד שם. הארגומנט השלישי, f, הוא מצביע לFILE שממנו יקראו התווים.
|
|
כדאי לדעת: בקלט מחרוזות השתמשנו בפונקציה זו, וכארגומנט השלישי העברנו stdin. מיד נעסוק בכך, בזרמים סטנדרטיים. |
עוד פונקציות[]
הספריה הסטנדרטית כוללת עוד פונקציות קלט מקבצים, לדוגמה fread.
זרמים סטנדרטיים[]
הספריה הסטנדרטית מגדירה שלושה מצביעים ל"קבצים" שלמעשה אינם לרוב קבצים אמיתיים, אלא צורות תקשורת עם המשתמש:
- stdin הוא מצביע ל"קובץ" שהוא למעשה המקלדת.
- stdout הוא מצביע ל"קובץ" שהוא למעש המסך.
- stderr הוא מצביע ל"קובץ" שהוא למעשה גם כן המסך, אלא שהוא משמש לפלט שגיאות.
אפשר להשתמש במצביעים אלה בפונקציות פלט הקבצים ובפונקציות קלט הקבצים. לדוגמה, היינו יכולים לכתוב את שלום עולם! כך:
#include <stdio.h>
int main()
{
fprintf(stdout, "Hello world\n");
return 0;
}
|
|
שימו לב: אין לנסות לפתוח "קבצים" אלה בעזרת fopen או לנסות לסוגרם בעזרת fclose. |
שינוי ומציאת המיקום בקובץ[]
כשאנו כותבים לקובץ וקוראים ממנו, אין מניעה (לרוב) לחזור אחורה או לדלג קדימה. ולהמשיך את הקריאות והכתיבות ממקום אחר. בנושא זה נראה כיצד לעשות זאת.
הפונקציה fseek[]
זזים ממקום למקום, על ידי fseek, בצורה הזאת:
fseek(<f>, <offset>, <origin>);כאשר:
- f הוא מצביע לFILE.
- offset הוא מספר הבתים שיש לזוז (מספר זה יכול להיות גם שלילי).
- origin הוא מוצא התזוזה, והוא יכול להיות אחת משלוש האפשרויות הבאות:
- SEEK_CUR - המיקום הנוכחי
- SEEK_SET - תחילת הקובץ
- SEEK_END - סוף הקובץ
לדוגמה:
fseek( file, 2L, SEEK_CUR );יזיז את המיקום 2 בתים קדימה מהמיקום הנוכחי. הפעולה הבאה שנעשה (קריאה או כתיבה) תתבצע במיקום החדש.
|
|
שימו לב: ההזזות השימושיות היחידות שבטוחות לביצוע במצב טקסט הן קפיצה לתחילת הקובץ או לסופו, כלומר:fseek( file, 0L , SEEK_SET );
fseek( file, 0L , SEEK_END ); |
הפונקציה ftell[]
הפונקציה הנוכחית מחזירה את המיקום הנוכחי. קטע הקוד הבא מראה דוגמה לקריאה לפונקציה:
long pos = ftell( file );לאחר קריאה זו, pos יכיל את מספר הבתים מתחילת הקובץ ועד המיקום הנוכחי.
פונקציה זו שימושית בעיקר בשילוב עם fseek. שומרים את המיקום הנוכחי, מבצעים פעולות קריאה וכתיבה כלשהן, וחוזרים למקום הנוכחי בעזרת fseek.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
הקדם מעבד
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C הקדם מעבד (preprocessor בלעז) הוא יישום הפועל על קבצי התוכנית לפני פעולתו של המהדר, ויכול לשנות את הטקסט שאותו מהדרים.
מהו הקדם מעבד?[]
הקדם מעבד פועל על קבצי טקסט, ויכול לערוך את הקוד לפני שהמהדר מהדר אותו. הקדם מעבד סורק קבצי טקסט, ומחפש פקודות המתחילות בתו #. כל פעולה כזו מחליפה קטע טקסט בקטע טקסט אחר.
|
|
שימו לב: הקדם מעבד אינו "מבין" את שפת C - הוא פועל על קטעי טקסט בלבד, בלי קשר לשאלות האם הוא עורך קטעי קוד תקינים, או האם לאחר העריכה התקבל קוד תקין. מסיבה זאת, הקדם מעבד מוגבל פחות מהמהדר, והוא רב עוצמה אך מסוכן. |
בפרק זה לא נתמקד בפעולות שאפשר לבצע בעזרת הקדם מעבד (נושא לספר שלם בפני עצמו), אלא רק בפעולות שקשה (או בלתי אפשרי) לבצע בלעדיו, ואפשר (בזהירות רבה) לבצע אתו.
שלבי ההידור[]
כאשר אנו מהדרים קובץ, מתרחשים למעשה שני שלבים:
- הפקודה מפעילה ראשית את הקדם מעבד. הוא קורא את הקובץ, משנה (אולי) את התוכן שקרא, ולאחר מכן,
- המהדר מקבל את תוצאת השלב הראשון, ומהדר אותה
לכן, על אף שעד עתה דיברנו בספר על הידור קבצים, מדובר ביתר דיוק בשני שלבים, וכך נתייחס אליהם בפרק זה. עם זאת, נשים לב שאין צורך בפקודה מיוחדת כדי להפעיל את הקדם-מעבד.
הגדרת קבוע[]
אפשר להשתמש בקדם-מעבד כדי להגדיר קבועים. לדוגמה, אפשר לקבוע שהקבוע RED הוא 1 (מיד נראה כיצד). כאשר הקדם-מעבד יגיע לרצף האותיות RED, הוא יחליף זאת ב1.
לדוגמה:
printf("%d", RED);ידפיס 1. הקדם-מעבד יהפוך את הקטע לקטע הבא:
printf("%d", 1);והמהדר כמובן יהפוך זאת לקוד שמדפיס 1.
הגדרת קבוע בקוד[]
מגדירים קבוע בקוד כך:
#define <const> <val>כאשר const הוא הקבוע, וval הוא הערך.
לדוגמה, נוכל לכתוב תוכנית כזו, שתדפיס 1:
#include <stdio.h>
#define RED 1
int main()
{
printf("%d", RED);
return 0;
}הנה עוד דוגמה, בה נכתוב מחדש את שלום עולם!:
#include <stdio.h>
#define GREETING "Hello, world"
int main()
{
printf(GREETING);
return 0;
}
|
|
כדאי לדעת: בתחליפים לחלק מיכולות הקדם מעבד נראה תחליפים טובים יותר לדוגמאות אלו. |
אפשר אפילו להודיע שקבוע מסויים מוגדר, אפילו בלי להגדיר שהוא מוגדר למשהו מסויים (נראה את השימוש לכך בהידור מותנה). עושים זאת בצורה:
#define <const>כאשר const הוא קבוע. לדוגמה, השורה:
#define REDמודיעה שהקבוע RED מוגדר, אבל איננה מגדירה אותו לערך מסויים.
הגדרת קבוע בפקודת ההידור[]
לא חייבים להגדיר כל קבוע בתוך הקוד. אפשר גם להגדיר קבוע בפקודת ההידור.
#include <stdio.h>
int main()
{
printf("%d", RED);
return 0;
}הדבר משתנה בין המערכות השונות.
gcc בלינוקס או Cygwin[]
כדי להגדיר שקבוע כלשהו מוגדר לערך כלשהו, כותבים
gcc -D<const>=<val> <source_file> -o <executable>כאשר const הוא הקבוע, val הוא ערכו, ו(כפי שראינו בבניית והרצת שלום עולם!), source_file הוא שם קובץ הקוד, וexecutable הוא שם קובץ התוכנית המתקבלת. לדוגמה,
gcc -DRED=1 red_test.c -o red_test.outתהדר את הקובץ red_test.c, ובכל מקום בו תזהה בו את הרצף RED, היא תחליפו ל1.
כדי להגדיר שקבוע כלשהו סתם מוגדר (לא לערך כלשהו), כותבים
gcc -D<const> <source_file> -o <executable>כאשר const הוא הקבוע, וכל השאר כמקודם. לדוגמה,
gcc -DDEBUG red_test.c -o red_test.outתהדר את הקובץ red_test.c, ותזהה שהקבוע DEBUG מוגדר (נראה את השימוש לכך בהידור מותנה).
סביבת פיתוח בחלונות[]
ב-Microsoft Visual Studio תוכלו להוסיף קבוע הידור בהגדרות הפרוייקט כולו או עבור כל קובץ הידור בנפרד. כדי לעשות זאת יש להכנס להגדרות הפרוייקט (Project -> Properties) או הקובץ (קליק ימני על הקובץ בחלון ה-Solution Explorer ומהתפריט לבחור Properties) ובהגדרות הקדם-מעבד (Preprocessor) להוסיף את הקבועים הרצויים בשדה Preprocessor Definitions.
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
כללים סגנוניים לגבי שמות קבועים[]
יש המקפידים על כך שכל קבוע הידור יורכב אך ורק מאותיות אנגליות עיליות (capital letters), קווים תחתונים, ומספרים. זאת כדי לזהות שמדובר בקבוע הידור. לפי שיטה זו, ההגדרה הבאה היא בסדר:
#define MY_COLOR 1אך ההגדרה הבאה איננה:
#define MyColor 1מומלץ לא להתחיל קבוע הידור בקו תחתון, ובשום פנים ואופן אין להתחיל קבוע הידור בשני קווים תחתונים. השורה הבאה, לדוגמה:
#define __MY_COLOR 3עלולה לגרום לתוצאות לא צפויות במערכות שונות.
קבועים מקובלים[]
ישנם מספר קבועים בעלי משמעות מקובלת:
- הקבוע DEBUG מציין שמהדרים קוד בגרסה לתיקון שגיאות.
- הקבוע NDEBUG מציין שמהדרים קוד בגרסה שאיננה כוללת תיקון שגיאות.
- הקבוע __FILE__ תמיד מוחלף על ידי הקדם-מעבד לקובץ שבתוכו הוא מופיע.
- הקבוע __LINE__ תמיד מוחלף על ידי הקדם-מעבד למספר השורה שבה הוא מופיע.
יש עוד מספר קבועים מקובלים, אך אלה הם העיקריים.
|
|
עכשיו תורך: הקוד הבא נשמר בקובץ preproc_test.c. מה תדפיס התוכנית? |
#include <stdio.h>
int main()
{
printf("Hello world from line %d of file %s", __LINE__, __FILE__);
return 0;
}
פתרון
Hello world from line 6 of preproc_test.c
הכלת קבצים[]
במהלך הספר נתקלנו מספר פעמים בשורות כגון:
#include <stdio.h>שורות אלו גורמות לקדם-מעבד להכיל קובץ אחד בתוך קובץ שני.
נניח שהתוכן של הקובץ foo.h הוא:
int foo();
void bar();נניח גם שהתוכן של הקובץ foo.c הוא:
#include "foo.h"
int main()
{
return 0;
}כלומר, שורה להכלת הקובץ foo.h, ולאחריה שורות תוכן אחרות. כאשר נהדר את הקובץ foo.c, ראשית יכיל הקדם-מעבד את תוכן foo.h במקום השורה הנ"ל. כלומר, המהדר למעשה יהדר את התוכן:
int foo();
void bar();
int main()
{
return 0;
}
נדון בשימוש הנפוץ של הכלת קבצים כשנגיע להכלת קבצי כותרת.
הידור מותנה[]
בעזרת הקדם-מעבד אפשר לקבוע שקטע קוד יהודר אך ורק בהתאם לשאלה האם קבוע הוגדר.
התנייה בהגדרת קבוע[]
נתבונן בקטע הקוד הבא:
#ifdef DEBUG
int is_sorted(const int *a, unsigned int length)
{
for(i = 1; i < length; ++i)
if(a[i] < a[i - 1])
return 0;
return 1;
}
#endif /* ifdef DEBUG */זהו קטע קוד שעטוף בזוג #ifndef-#endif. הקוד במקרה זה הוא פונקציה is_sorted, המקבל מערך באורך נתון, ובודק האם המערך המערך ממויין (בסדר עולה).
כאשר מגיעים לקטע קוד זה, יש שתי אפשרויות: הקבוע DEBUG מוגדר או לא. אם הקובע DEBUG מוגדר, אז הקדם מעבד יחליף את הקטע הנ"ל בקטע:
int is_sorted(const int *a, unsigned int length)
{
for(i = 1; i < length; ++i)
if(a[i] < a[i - 1])
return 0;
return 1;
}אם הקובע DEBUG אינו מוגדר, אז הקדם מעבד יחליף את הקטע הנ"ל בקטע:
כלומר בקוד ריק.
לסיכום, חלק הקוד בין #ifdef DEBUG לבין #endif יהודר אך ורק אם DEBUG מוגדר בנקודה זו.
באופן כללי, מסמנים התניה בהגדרת קבוע בצורה:
#ifdef <const>
...
#endifכאשר const הוא קבוע.
התניה באי-הגדרת קבוע[]
אפשר גם לקבוע שקטע קוד יהודר אך ורק אם קבוע אינו מוגדר. עושים זאת בצורה:
#ifndef <const>
...
#endifכאשר const הוא קבוע.
שימושים[]
קוד לניפוי שגיאות[]
אחד השימושים הנפוצים בקדם-מעבד הוא להידור מותנה של קטעי קוד שלמים שכל מטרתם היא ניפוי שגיאות. בדרך כלל אפשר לזהות קוד זה כך:
#ifdef DEBUG
...
#endif /* ifdef DEBUG */נשים לב לשימוש בקבוע המקובל DEBUG.
נראה דוגמה לכך בדוגמה לקוד לניפוי שגיאות.
קבצי כותרת[]
|
|
שקול לדלג על נושא זה שקול לחזור לכאן במהלך קריאתך את מודולים. |
שיטה מקובלת בתכנות C היא סימון קבצי כותרת בהתניה. קבצי כותרת לעתים קרובות נראים מהצורה:
#ifndef <const>
#define <const>
...
#endifכאשר const הוא קבוע כלשהו. כלומר, כל תוכן הקובץ נמצא בין רצף #ifndef-#define ל#endif.
אם נתבונן בקובץ ששמו file_1.h, לדוגמה - תוכנו עשוי מאד להראות כך:
#ifndef FILE_1_H
#define FILE_1_H
...
#endif /* ifndef FILE_1_H */
אוסף הפקודות הזה מביא לכך שתוכן הקובץ מוכלל אך ורק פעם אחת:
- בפעם הראשונה בה הקובץ נקרא, מוגדר הקבוע const (כאן, לדוגמה, FILE_1_H).
- בפעמים הבאות בהן הקובץ נקרא, הקבוע כבר מוגדר. היות שתוכן הקובץ עטוף בזוג
#ifndef-#endif- המהדר יתעלם ממנו.
הסיבה לשימוש בסימון זה היא שפעמים רבות ייקראו קבצי כותרת פעמים רבות (לפעמים מקבצי כותרת אחרים), מה שעלול לגרום לבעיות בהידור הקובץ (אם, למשל, יוגדר struct זהה יותר מפעם אחת - התוכנית תיכשל בשלב ההידור).
עניינים סגנוניים[]
הערות לסוגר תנאי[]
יש המוסיפים הערה ל#endif המציינת את תוכן השורה שהתחילה את הקטע, לדוגמה כך:
#ifdef DEBUG
...
#endif /* ifdef DEBUG */או כך:
#ifndef FILE_1_H
#define FILE_1_H
...
#endif /* ifndef FILE_1_H */הדבר עשוי לעזור למתכנתת להבין היכן החל קטע הקוד המותנה.
קבועים לקבצי כותרת[]
כאשר ממציאים קבוע לקובץ כותרת, רצוי לבחור בשיטה אחידה. שיטה אחת מקובלת היא להשתמש בשם הקובץ באותיות אנגליות גדולות, ולאחריו _H. כך, לדוגמה, אם קובץ הכותרת הוא file_1.h, אז הקבוע בשיטה זו יהיה FILE_1_H:
#ifndef FILE_1_H
#define FILE_1_H
...
#endif /* #ifndef FILE_1_H */המאקרו assert[]
המאקרו assert הוא כלי מועיל לניפוי שגיאות.
|
|
כדאי לדעת: קטעי הקוד שבנושא זה משתמשים בספרייה הסטנדרטית. נדון בספריות באופן מעמיק יותר כאן. לעת עתה, פשוט יש לזכור לרשום בראשי הקבצים המשתמשים בקטעי הקוד שבנושא זה#include <assert.h> |
הבעיה[]
נתבונן בקטע הקוד הבא:
void foo(int x)
{
float y = 1.0 / x;
...
}קל לראות שתתרחש טעות אם x = 0 בזמן הקריאה, אך נניח שאנו יודעים שהפוקנציה foo לא תיקרא לעולם כאשר x = 0, כי חלקים אחרים בקוד דואגים לכך. מה יקרה אם יש שגיאה בחלקי הקוד הדואגים לכך? ברוב המערכות, התוכנית תיעצר, ותודפס הערה קצרה למדי. קשה יהיה להבין אפילו איזו שורה גרמה לטעות.
כדי להתמודד עם זאת, היינו יכולים לכתוב את הפונקציה כך (הנח ששם הקובץ הוא test.c, והפונקציה כתובה באיזור שורה 80):
void foo(int x)
{
if(!(x != 0))
{
printf("Assertion failed: 'x != 0' in line 80 test.c");
exit(-1);
}
float y = 1.0 / x;
...
}אך יש מספר בעיות עם פתרון זה:
- הקוד הופך להיות פחות יעיל, מפני שאם אכן x לעולם אינו 0 - ביצענו בדיקה מיותרת.
- הקוד מסורבל יותר; קשה יותר להבין מה הפונקציה עושה.
- אם נעביר את הקוד לקובץ אחר או לשורה אחרת - הודעת השגיאה המודפסת סתם תבלבל.
כדי לפתור זאת, נוכל להשתמש בהתניה באי-הגדרת קבוע ובקבועים מקובלים, כך:
void foo(int x)
{
#ifndef NDEBUG
if(!(x != 0))
{
printf("Assertion failed: 'x != 0' in line %d %s", __LINE__, __FILE__);
exit(-1);
}
#endif /* #ifndef NDEBUG */
float y = 1.0 / x;
...
}אך הקוד הופך להיות אפילו יותר מסורבל.
כעת נראה איך להשתמש במאקרו assert להשגת אותה התוצאה, אך בפחות סרבול.
השימוש במאקרו[]
משתמשים במאקרו assert בצורה הבאה:
assert(<cond>);כאשר cond הוא ערך בוליאני. לדוגמה, אפשר לכתוב כך:
assert(x != 0);אם התנאי לא יתקיים - התוכנית תדפיס הודעה כזו:
Assertion failed: 'x != 0' in line 80 test.cותעצר.
אם יש שורה שלעולם אין להגיע אליה, אפשר לכתוב:
assert(0);אם בכל אופן התוכנית תגיע לשורה אי פעם (כלומר - יש טעות בקוד), התוכנית תדפיס הודעה כזו:
Assertion failed: 0' in line 100 foo.cותעצר.
דוגמאות[]
נוכל להשתמש במאקרו כדי לפתור את הבעיה הקודמת שראינו:
void foo(int x)
{
assert(x != 0);
float y = 1.0 / x;
...
}לפעמים גם מוסיפים את המאקרו בswitch-case שלא אמור לקבל ערך ברירת-מחדל לעולם. לדוגמה, נתבונן בקטע הבא:
switch(b)
{
case 1:
...
case 3:
...
case 15:
...
};
...קטע הקוד עשוי להתאים למצב בו b אמור לקבל בדיוק אחד משלושת הערכים 1, 3, ו15. במקרה זה, נוכל להוסיף את החלק הבא:
switch(b)
{
case 1:
...
case 3:
...
case 15:
...
default:
assert(0);
};
...כך, אם אירעה שגיאה בקוד, נקבל הודעת שגיאה מתאימה.
דוגמה לקוד לניפוי שגיאות[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
#include <assert.h>
#ifdef _DEBUG
int is_sorted(const int *a, unsigned int length)
{
for(i = 1; i < length; ++i)
if(a[i] >= a[i - 1])
return 0;
return 1;
}
#endif /* ifdef DEBUG */
int main()
{
int a[] = {2, 3, 5};
assert( is_sorted(a, 3) );
print( binary_search(a, 3, 10) );
return 0;
}תחליפים לחלק מיכולות הקדם מעבד[]
לקדם מעבד עוד יכולות מספר. נעבור על חלקן בקצרה, ונציג תחליפים להן.
הקדם מעבד יכול להחליף מופע טקסט בטקסט אחר. לדוגמה, הפקודה:
#define RED 2
#define BLUE 3תגרום לכך שבכל מקום בהמשך הקובץ בו מופיע הרצף RED, הוא יוחלף ב2.
במקום זאת אפשר להשתמש במשתנים קבועים:
const int red = 2;
הקדם מעבד גם מאפשר להגדיר פקודות מאקרו, שהן כמעין פונקציות פשוטות. לדוגמה, הפקודה:
#define MIN(a, b) a < b? a: bתגרום לכך שבכל מקום בהמשך הקובץ בו מופיע הרצף MIN(2, 3), הוא יוחלף ב2 < 3? 2: 3.
במקום זאת אפשר פשוט להשתמש בפונקציה רגילה:
int min(int a, int b)
{
return a < b? a: b;
}
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
מודולים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
| |
הערך נמצא בשלבי עריכה הנכם מתבקשים שלא לערוך ערך זה בטרם תוסר הודעה זו כדי למנוע התנגשויות עריכה. שימו לב! אם דף זה לא נערך במשך שבוע, רשאי כל ויקיפד להסיר את התבנית ולהמשיך לערוך אותו. |
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
חלוקת הקוד למודולים (קבצי קוד) מסייעת לתחזוקתו ומייעלת את בנייתו לתוכנית.
|
|
שקול לדלג על נושא זה נושא זה שימושי בעיקר אם אתה כותב תוכניות גדולות. בנוסף, התוכן מניח שאתה כבר מבין את עקרונות חלוקת הקוד לפונקציות, ומבין את הצורך והשימוש בהצהרות פונקציות. |
הצורך במודולים[]
שפת C משמשת לכתיבת תוכנות מסובכות מאד. הקוד של ליבת לינוקס, לדוגמה, מורכב ממיליוני שורות קוד. ברור למדי שלא ייתכן לתחזק קובץ קוד אחד ענק שיכיל מיליוני שורות קוד. הדבר היה יוצר קשיים רבים:
- קשיים אנושיים:
- לבני אדם קשה "למצוא את הידיים והרגליים" בקובץ ענק.
- בפרוייקט תוכנה מסדר גדול, סביר להניח שיותר מאדם אחד עובד על הקוד באותו פרק זמן. קובץ יחיד אינו פתרון טוב במצב כזה - רק אדם יחיד יכול לעבוד עליו בכל פרק זמן.
- בזבוז משאבי מחשב - אם כל הקוד היה מרוכז בקובץ יחיד, אז כל שינוי בקובץ היה מצריך את הידור כל הקוד מחדש.
בפרק זה נלמד כיצד לחלק את הקוד למודולים, או קבצי קוד שכל אחד מהם מכיל את חלקי הקוד המתאימים לנושא אחד בלבד.
דוגמה לחלוקה למודולים[]
להלן דוגמה רצה, בה נשתמש בפרק זה. הקובץ הבא מראה ארבע פונקציות:
void g1();
void f1()
{
g1()
}
void g1()
{
...
}
void f2()
{
...
}
void g2()
{
...
g1();
...
f1();
...
}טכנית, הפונקציות קשורות זו בזו כך:
- f1 משתמשת בg1
- g1 אינה משתמשת באף פונקציה אחרת
- f2 אינה משתמשת באף פונקציה אחרת
- g2 משתמשת בg1 ובf1
בלי קשר, הוחלט שהקובץ מכיל פונקציות משני נושאים שונים, ואפשר (וכדאי) לחלקו לשני קבצים. (כמובן שבמציאות, דוגמה טובה יותר היתה ארוכה פי כמה.) המתכנתים שמו לב שf1 וg1 מטפלות בנושא אחד, וf2 וg2 מטפלות בנושא אחר. הוחלט, לכן, לכתוב שני קבצים, file_1.c וfile_2.c, ולהעביר אליהם את תוכן הקובץ הקודם. כך נראה file_1.c:
void g1();
void f1()
{
g1()
}
void g1()
{
...
}וכך נראה file_2.c:
void f2()
{
...
}
void g2()
{
...
g1();
...
f1();
...
}כך הקוד מופרד לנושאים. הוא נוח יותר לתחזוקה למתכנתים, ויעילי יותר לבנייה לתוכנית. עם זאת, יש לפתור עוד מספר נושאים טכניים כדי שהקוד אכן יהיה חוקי (כפי שהוא מוצג כעת, המהדר יתלונן). שאר הפרק דן בכך.
שלבי בניית התוכנית[]
כדי להבין פרק זה, יש להבין כיצד בונים תוכנית מקוד C. נשתמש בדוגמה לחלוקה למודולים.
התרשים הבא מראה באופן גרפי את שלבי בניית התוכנית:
{kind=link}
- ראשית מהדרים את קבצי המקור לקבצי ביניים:
- המהדר מהדר את file_1.c לקובץ ביניים file_1.obj.
- המהדר מהדר את file_2.c לקובץ ביניים file_2.obj.
- לאחר מכן מקשרים: המקשר מקשר את שני קבצי הביניים לprogram.out שהוא קובץ תוכנית הניתן להרצה (executable בלעז).
נשים לב למספר נקודות:
- אם משנים את אחד הקבצים, נניח file_2.c, אז אין צורך להדר מחדש את file_1.c. מספיק להדר מחדש את הקובץ שהשתנה, ולקשר את קבצי הביניים.
- פעולות ההידור תמיד נעשית לפני פעולת הקישור.
קבצי כותרת[]
הצורך בקבצי כותרת[]
נחזור לדוגמה לחלוקה למודולים. לאחר החלוקה לשני קבצים, כך נראה file_2.c:
void f2()
{
...
}
void g2()
{
...
g1();
...
f1();
...
}אם ננסה לבנות את התוכנית, המהדר יתלונן. ניזכר בצורך להצהיר על פונקציות, ונראה את הבעיה כאן. כשהמהדר מגיע לשורות:
g1();
...
f1();הוא אינו יודע מהן הפונקציות האלה; הן הוגדרו בכלל בfile_2.c. אמנם נכון שאנו מתכוונים לקשר את קבצי הביניים של שני file_1.c וfile_2.c, אך כפי שמראה התרשים בשלבי בניית התוכנית, המהדר פועל לפני המקשר, והוא אינו יודע זאת.
מהו קובץ כותרת?[]
קובץ כותרת בנוי בדרך כלל בצורה הבאה:
#ifndef <preproc_def>
#define <preproc_def>
<declarations>
#endif /* #ifndef <preproc_def> */כאשר preproc_def הוא קבוע הידור, וdeclarations הם הצהרות.
לדוגמה, file_2.h יכול להיראות כך:
#ifndef FILE_1_H
#define FILE_1_H
void f1();
void g1();
#endif /* #ifndef FILE_1_H */כאן FILE_1_H הוא קבוע ההידור, וההצהרות הן:
void f1();
void g1();הכלת קבצי כותרת[]
#include "file_1.h"
void f2()
{
...
}
void g2()
{
...
g1();
...
f1();
...
}צמד הקבצים הקלאסי[]
file_1.h
#ifndef FILE_1_H
#define FILE_1_H
void f1();
void g1();
#endif /* #ifndef FILE_1_H */file_1.c
#include "file_1.h"
void f1()
{
g1()
}
void g1()
{
...
}file_2.h
#ifndef FILE_1_H
#define FILE_1_H
void f2();
void g2();
#endif /* #ifndef FILE_1_H */file_2.c
#include "file_1.h"
#include "file_2.h"
void f2()
{
...
}
void g2()
{
...
g1();
...
f1();
...
}בניית הדוגמה[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
gcc בלינוקס או Cygwin[]
ראשית, נהדר את הקבצים:
gcc -Wall -c file2.c
הפעולה תיצור לנו את הקבצים file1.o ו-file2.o, שהם קבצים מהודרים, אך עדיין אינם קבצי הרצה. כעת נבצע את פעולת הקישור (Linkage):
פקודה זו תיצור קובץ הרצה בשם program. לחילופין, ניתן לבצע את כל הפעולות האלה בבת אחת:
יש לזכור שגם כאשר מהדרים את התוכנית בדרך זו, עדיין מתבצעות הפעולות לפי סדר: בתחילה, מתבצע הידור על כל הקבצים ואז מתבצע הקישור, בדיוק כמו שהתבצע כאשר עשינו זאת צעד אחר צעד.
|
|
כדאי לדעת: הדגל -Wall מסמן למהדר להתריע על כל Warning אפשרי (כלומר - בעייה בקוד שאינה חמורה עד כדי כך שתמנע את ההידור). הוא לא הכרחי, אך עם זאת כדאי להתרגל להשתמש בו מכיוון שהאזהרות שהמהדר מנפק הן כמעט תמיד סימן לבעייה הדורשת תיקון. |
סביבת פיתוח בחלונות[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
גישה למשתנים ממודולים אחרים[]
משתנים סטטיים[]
ניתן להוסיף את המילה השמורה static לפני כל הצהרה על משתנה. להוספת מילה זו יש שתי השפעות שונות, בהתאם לסוג המשתנה שאליו היא הוספה. כאשר מוסיפים אותה לפני משתנה גלובלי, פירוש הדבר הוא שהמשתנה הזה יהיה נגיש רק בתוך הקובץ שבו הוא הוגדר, ולא בקבצים אחרים שאולי יעברו קומפילציה עם התוכנית בהמשך. הדבר שימושי כאשר רוצים להשתמש בשמות נפוצים עבור משתנים ולמנוע התנגשויות.
(מילת המפתח static משמשת גם לדבר שונה לחלוטין. ראה כאן.)
דוגמה: חזרה לרשימות מקושרות[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
list.h
#ifndef LIST_H
#define LIST_H
struct link_
{
struct link_ *next;
int data;
};
typedef struct link_ link;
struct list_
{
link *head;
unsigned long size;
};
typedef struct list_ list;
void list_ctor(list *list);
void list_dtor(list *list);
unsigned long list_size(const list *list);
int list_push(list *list, int d);
int list_pop(list *list);
int list_head(const list *list);
#endif /* #ifndef LIST_H */list.c
#include "list.h"
#include <stddef.h>
#include <malloc.h>
void list_ctor(list *list)
{
list->head = NULL;
list->size = 0;
}
void list_dtor(list *list)
{
link *l = list->head;
while(l != NULL)
{
link *const old = l;
l = old->next;
free(old);
}
list_ctor(list);
}
unsigned long list_size(const list *list)
{
return list->size;
}
int list_push(list *list, int d)
{
link *const l = (link *)malloc(sizeof(link));
if(l == NULL)
return -1;
l->data = d;
l->next = list->head;
list->head = l;
++list->size;
return 0;
}
int list_pop(list *list)
{
link *const l = list->head;
const int d = l->data;
list->head = l->next;
--list->size;
free(l);
return d;
}
int list_head(const list *list)
{
const link *const l = list->head;
return l->data;
}main.c
#include <stdio.h>
#include "list.h"
int main()
{
int c;
list lst;
list_ctor(&lst);
do
{
int d;
printf("Please enter a number: ");
scanf("%d", &d);
list_push(&lst, d);
printf("Please enter 0 to quit, or any other number to continue: ");
scanf("%d", &c);
}
while(c != 0);
printf("The numbers you entered, in reverse order, are:\n");
while(list_size(&lst) > 0)
printf("%d\n", list_pop(&lst));
list_dtor(&lst);
return 0;
}
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
שימוש בספריות
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C שפת C מתוכננת כשפה קטנה. פעולות מועילות רבות (כגון פלט וקלט) אינם חלק מהשפה, אלא מרוכזות בספריות - קבצים המכילים קטעי קוד המוכנים לשימוש. אנו נתמקד בפרט בספריה הסטנדרטית, המותקנת יחד עם המהדר.
מעט על קבצי כותרת[]
קובץ כותרת (header file בלעז) הוא קובץ שמכיל לרוב הצהרות על פונקציות, או, במילים אחרות, תאור למהדר לגבי פונקציות שמוגדרות במקום אחר. לקבצי כותרת בשפת C יש לרוב הסיומת .h (לדוגמה, stdio.h). תוכל לקרוא עוד על קבצי כותרת בהכלת קבצים על ידי הקדם מעבד.
צעדי השימוש בספריות[]
כאשר כותבים קוד, לפעמים מזהים צורך בפעולה מועילה שכיחה למדי - שכיחה במידה כזו שייתכן שהיא חלק מספרייה. להלן מספר פעולות שסביר להניח שאינך הראשון שנדרש להן:
- השוואה בין שתי מחרוזות
- חישוב הפונקציה הטריגונומטרית סינוס
- הדפסת הזמן בשעון המחשב
אם זה המצב, כדאי להשתמש בספריה אם אפשר. כדי להשתמש בספריה, יש צורך בפעולות הבאות:
- מציאת הספריה המתאימה
- מציאת קובץ הכותרת המתאים
- הוספת פקודה להכלת קובץ הכותרת
- קישור הספריה
בקוד עצמו אפשר להשתמש בפונקציות ומבני הספריה בצורה רגילה לחלוטין.
מציאת הספריה המתאימה[]
ראשית עליך למצוא את הספריה המתאימה לפעולה שאתה מחפש. אין דרך מסודרת לעשות זאת (ייתכן שתיאלץ לחפש באינטרנט, לדוגמה). בפרק זה נתמקד מכל מקום רק בספריה אחת - הספריה הסטנדרטית המגיעה עם המהדר.
מציאת קובץ הכותרת המתאים בספרייה[]
את קובץ הכותרת המתאים תצטרך לחפש בתיעוד הנלווה לספרייה שבה אתה משתמש. כאן, לדוגמה, תוכל לראות רשימה של קבצי הכותרת של הספריה הסטנדרטית ותיאור קצר של כל אחת מהן. להלן פירוט קצר ביותר של חלק קטן מהן:
- הקובץ stdio.h עוסק בקלט ופלט. בשלום עולם!, פלט וקלט, מחרוזות, ופלט וקלט קבצים השתמשנו בפונקציות printf, scanf, getchar, putchar, gets, puts ובמבנה FILE מתוכו.
- הקובץ string.h עוסק במחרוזות. במחרוזות השתמשנו בפונקציות strlen, strcpy, strcat מתוכו.
- הקובץ stdlib.h כולל פעולות סטדנדריות רבות באופן כללי. בניהול זיכרון דינאמי השתמשנו בפונקציות malloc, free, callc, realloc מתוכו.
- הקובץ math.h כולל פונקציות מתמטיות רבות, לדוגמה פונקציות טריגונומטריות.
- הקובץ assert.h כולל את המאקרו assert, אותו ראינו בקדם מעבד.
הפקודה להכלת קובץ הכותרת[]
כדי להכיל קובץ כותרת, לדוגמה stdlib.h, יש לכתוב
#include <stdlib.h>תוכל לקרוא עוד על הסימון # בקדם מעבד.
קישור הספריה[]
באופן כללי, יש להודיע למקשר לקשר את הספריה יחד עם הקוד שכותבים. לא נדון כאן כיצד עושים זאת. עם זאת, אין צורך לעשות כן כאשר מדובר בספריה הסטנדרטית.
דוגמה: חישוב סינוס[]
נניח שאנו רוצים לקלוט מעלה (ברדיאנים) מהמשתמש, ולחשב את הסינוס שלו. שפת C איננה כוללת פקודה מיוחדת לחישוב סינוס (או כל פונקציה טריגונומטרית אחרת), אך כבר ראינו שהשפה כוללת פעולות חשבוניות. נוכל להשתמש בטור טיילור, לכן, כפי שעשינו בתרגיל קירוב סינוס על ידי טור טיילור. הנה הפיתרון המופיע שם, המתבסס על קירוב ע"י 10 האיברים הראשונים בטור:
#include <stdio.h>
int main()
{
float angle;
unsigned int i;
float sinus = 0;
int sign = 1;
unsigned long int factorial = 1;
float power;
printf("Please enter angle: ");
scanf("%f", &angle);
power = angle;
for(i = 0; i < 10; ++i)
{
sinus += sign * power / factorial;
sign = -sign;
factorial *= (2 * i + 2) * (2 * i + 3);
power *= angle * angle;
}
printf("sin(%f) ~= %f\n", angle, sinus);
}פיתרון זה מצריך אותנו לבדוק מהו טור טיילור המתאים ולקודד אותו, פעולה בעלת סיכוי לא-זניח לשגיאות. יותר מכך, הפיתרון המופיע כאן אינו מושלם:
- מדוע החלטנו להשתמש דווקא ב10 איברים?
- מה בכלל ערך השגיאה? האם לקחנו בחשבון שערך השגיאה גדל יחד עם המעלה הנקלטת (בערך מוחלט)?
- האם כלל השתמשנו במחזוריות סינוס?
מובן שאפשר למצוא פתרון מתוחכם קצת יותר, אך ככל שנתחכם יותר, כך גדל הסיכוי שבזבז זמן בכתיבה ובתיקון. זה מיותר, מפני שסביר להניח שאיננו הראשונים להזדקק לסינוס בשפת C.
במקום זאת נשתמש בספריה הסטנדרטית. נחפש כאן מהו קובץ הכותרת המתאים. ניחוש הגיוני הוא math.h. עיון בתיעוד שלו מלמד שאכן יש בו פונקציית סינוס. נשתמש בה, לכן:
#include <stdio.h>
#include <math.h>
int main()
{
float angle;
printf("Please enter angle: ");
scanf("%f", &angle);
printf("sin(%f) ~= %f\n", angle, sin(angle));
}זוהי אלטרנטיבה קצרה ובטוחה יותר.
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
נספחים
נמצאה תבנית הקוראת לעצמה: תבנית:שפת C
טווחי טיפוסים שלמים[]
השפה קובעת שגודלו של char הוא בית אחד בדיוק. לגבי שאר הטיפוסים, השפה אינה מגדירה במדויק את גדלי וטווחי המשתנים. ברוב המחשבים, לדוגמה, משתנה שלם תופס 4 בתים, אך קיימים מעבדי 64-ביט שבהם משתנה שלם תופס 8 בתים. תקן השפה קובע לרוב רק טווחים מינימליים:
| טיפוס בסיסי | גודל (בבתים) | ערך מינימלי (signed) | ערך מקסימלי (signed) | ערך מקסימלי (unsigned) |
|---|---|---|---|---|
| char | 1 | -127 | 127 | 255 |
| short int | לפחות 2 | -32,767 | 32,767 | 65,535 |
| int | לפחות 2 | -32,767 | 32,767 | 65,535 |
| long int | לפחות 4 | -2,147,483,647 | 2,147,483,647 | 4,294,967,295 |
מילים שמורות[]
להלן פירוט של מילים שמורות, כלומר מילים שאין להשתמש בהן כשמות משתנים ופונקציות. מהפירוט למטה עולה שאין אחידות בנושא. חלק מהמילים הללו שמורות בכל המהדרים, חלק רק במהדרים חדישים מספיק, וחלק רק במהדרים שהחליטו על דעת עצמם שהמילים שמורות. כדאי בכל מקרה להמנע משימוש במילים אלה כשמות משתנים ופונקציות, גם אם המהדר בו אתה משתמש אינו מתייחס אליהן כך.
מילים שמורות סטנדרטיות[]
הרשימה הבאה מכילה מילים שמורות בכל מהדר תקני:
- auto
- break
- case
- char
- const
- continue
- default
- do
- double
- else
- enum
- extern
- float
- for
- goto
- if
- int
- long
- register
- return
- short
- signed
- sizeof
- static
- struct
- return
- switch
- typedef
- typedef
- unsigned
- void
- volatile
- while
מילים שמורות חדשות[]
מילים אלה הוגדרו כשמורות בתקן חדש יחסית, C99. לא כל המהדרים מכירים בהן:
- _Bool
- _Complex
- _Imaginary
- inline
- restrict
מילים שמורות בחלק מהמהדרים[]
חלק מהמהדרים מכירים במילים אלה כמילים שמורות, למרות שלפי התקן אינן:
- asm
- cdecl
- far
- fortran
- huge
- interrupt
- near
- pascal
- typeof
מילים לא-שמורות במהדרים ישנים מאד[]
מהדרים ישנים עשויים לא להכיר במילים אלה כשמורות:
- const
- enum
- signed
- void
- volatile
כמובן שמהדרים ישנים-מאד אלה גם אינם מכירים במילים השמורות החדשות שראינו.
דגלי הידור[]
מהם דיגלי הידור?[]
בתהליך הבניה, המהדר הופך את שורות הקוד שכתבנו לפקודות שאותן יכול המחשב לבצע. לרוב יש יותר מדרך אחת לבצע זאת. לדוגמה, לפעמים יכול המהדר לבנות מאותו קוד תוכנית קטנה אך איטית יחסית, או תוכנית מהירה אך גדולה יחסית. בזמן הבניה אפשר להודיע למהדר מהן העדפותינו.
דיגלי ההידור[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
רוב המערכות תומכים בדיגלי הידור רבים מאד. נציג כאן רק את החשובים שבהם. בדוגמאות שנראה, נניח שfile1.c ו-file2.c הם קבצי תוכניות שכתבנו.
- קביעת קובץ הפלט: הדגל
-o <file>מודיע למהדר מה שם קובץ הפלט שיווצר לאחר ההידור.- gcc בלינוקס או Cygwin: ברירת המחדל בלינוקס היא a.out כאשר מדובר בקובץ ריצה, וקובץ עם שם זהה אם מדובר בהידור בלבד ללא קישור (ראו בהמשך). דוגמת שימוש:gcc file1.c file2.c -o Program
- gcc בלינוקס או Cygwin: ברירת המחדל בלינוקס היא a.out כאשר מדובר בקובץ ריצה, וקובץ עם שם זהה אם מדובר בהידור בלבד ללא קישור (ראו בהמשך). דוגמת שימוש:
- קביעת רמת האזהרות:
- gcc בלינוקס או Cygwin: הדגל
-Wallמסמן למהדר לציין כל Warning אפשרי. Warning - אזהרה - הוא מונח בתכנות שמתייחס לבעיות בקוד שאינן מונעות לגמרי הידור, אבל ברוב המקרים מצביעות על בעייה מסויימת. דוגמה: הסבה ישירה של משתנים שהיא חוקית אך מסבה סוגים לא קשורים של משתנים. דוגמת שימוש:
- gcc בלינוקס או Cygwin: הדגל
- קישור בלבד: הדגל
-cמסמן למהדר שלא ליצור קישור אלא להדר בלבד. שימושי כאשר בונים פרוייקטים המורכבים מיותר מקובץ אחד, כאשר לא מעוניינים להדר ולקשר מחדש את כל הקבצים, אלא רק חלק מהם.- gcc בלינוקס או Cygwin: כברירת מחדל, הפעולה יוצרת קובץ בשפת מכונה, תחת שם זהה אך עם הקידומת .o, שאינו בר הרצה (ניתן לבחור כל שם קובץ אחר בעזרת הדגל -o). דוגמת שימוש:
לאחר מכן, ניתן לקשר את הקבצים שנוצרו בצורה הבאה, כאשר הפעולה הבאה תיצור קובץ הרצה בשם Program:
- הוספת מידע לניפוי שגיאות: הדגל
-gמסמן למהדר להוסיף סימונים מיוחדים שמסייעים לתוכנות ניפוי שגיאות.- gcc בלינוקס או Cygwin: אם אתם בודקים את הקוד בעזרת מנפה שגיאות כלשהו (gdb, למשל), יש להדר בעזרת הדגל הזה. אם תבדקו קובץ בעזרת Valgrind תוכלו לקבל מידע רב יותר על התקלות שיימצאו. דוגמת שימוש:
- הדגל
-Eמציג כיצד נראה הקובץ אחרי פעולת הקדם-מהדר. כאשר מפעילים את ה-gcc עם דגל זה לא מתבצע הידור כלשהו בפועל. דוגמת שימוש:
- הדגל
-O(שימו לב - O גדולה) יורה למהדר לבצע אופטימיזציה של התוכנית, כלומר - יבצע שינויים בקוד התוכנית כדי להביא לפעולה מהירה יותר. בדרך כלל ניתן להשיג שיפור מרשים בביצועים כאשר משתמשים באופטימיזציה. מצד שני, זוהי פעולה שעשויה לגרום לבעיות. יש כמה דרגות אפשריות של אופטימיזציה (מ-0 ועד 3), כאשר ככל שהדרגה גבוהה יותר מתבצעים שינויים רבים יותר והסכנה בפגמים שיווצרו - גדולה יותר. ככל שעולה דרגת האופטימיזציה גם ידרש המהדר לזמן פעולה ארוך יותר. הדגל -O (ללא מספר) מקביל לדרגה 1. עבור דרגות אחרות יש לכתוב בצמוד לאות O את דרגת האופטימיזיה: O1, O2 או O3 (ברירת המחדל, אם לא כותבים דגל כלל, היא O0). דוגמת שימוש:
אופטימיזציה בדרגה 3:
הידור (וקישור) במערכות שונות[]
gcc בלינוקס או Cygwin[]
אם תעבדו עם מהדר ה-gcc משורת הפקודה, ישנם כמה דגלים שכדאי להכיר.
סביבת פיתוח בחלונות[]
פרק זה לוקה בחסר. אתם מוזמנים לתרום לויקימחשבים ולהשלים אותו. ראו פירוט בדף השיחה.
קדימות ואסוציאטיביות אופרטורים[]
הטבלה הבאה מראה את הקדימות (precedence בלעז) והקישוריות (associativty בלעז) של האופרטורים בשפת C.
| אופרטור | קישוריות |
|---|---|
| () [] -> . | שמאל לימין |
| ! ~ ++ -- +אונרי- אונרי* אונרי & (<type>) sizeof | ימין לשמאל |
| * . % / | שמאל לימין |
| בינרי+ בינרי- | שמאל לימין |
| << >> | שמאל לימין |
| < <= > >= | שמאל לימין |
| == != | שמאל לימין |
| & | שמאל לימין |
| | | שמאל לימין |
| && | שמאל לימין |
| || | שמאל לימין |
| ?: | ימין לשמאל |
| = >>= <<= | ימין לשמאל |
| , | שמאל לימין |
אונרי כמו לדוגמה ב-3
בינרי כמו לדוגמה ב3 + 5
סדר הקדימות של אופרטורים הוא גבוה יותר ככל שמיקומם הוא בשורה גבוהה יותר (אופרטורים באותה שורה הם בעלי אותה קדימות). כך, לדוגמה, פרשנות הביטוי 13 / 5 + 2 היא (13 / 5) + 2 (כפי שנהוג באלגברה בסיסית), מפני ש/ מופיע בשורה גבוהה יותר מ+.
הקישוריות של אופרטורים קובע האם מספר אופרטורים כאלה ברצף מתקשרים משמאל לימין או ההיפך. לדוגמה, פרשנות הביטוי 2 - 3 - 4 היא ( 2 - 3) - 4, מפני שקישוריות - היא משמאל לימין.
סימונים בספר[]
סוגריים משולשים[]
לעתים אפשר לראות בספר הסברים כגון: "באופן כללי בונים קוד בצורה:
כאשר source_file הוא שם קובץ הקוד, וexecutable הוא שם קובץ התוכנית המתקבלת." (ראה, לדוגמה בניית התוכנית שלום עולם!).
כאשר רואים דבר כזה, יש להחליף את מה שנמצא בתוך הסוגריים המשולשים (לדוגמה source_file) במשהו אחר ללא הסוגריים המשולשים. לדוגמה, את הפקודה הקודמת אפשר להחליף במשהו כזה:
ולא כך:
היוצא היחידי מן הכלל הוא בשורות מהסוג:
#include <stdio.h>בהן אכן יש להשתמש בסוגריים משולשים.
קוד תוכניות לעומת קטעי קוד[]
בחלק מהמקומות בספר כתוב קוד המתאים לתוכניות שלמות. הקוד הבא, לדוגמה, מופיע בשלום עולם!:
#include <stdio.h>
int main()
{
printf("Hello world\n");
return 0;
}קוד זה מספיק לתוכנית מלאה. אפשר לבנות ממנו תוכנית, ולהריצה.
לעומת זאת, במקומות רבים אנו רוצים להתמקד בנקודה מסויימת. לדוגמה, במשתנים, מופיע קטע הקוד הבא:
int grade = 80;קטע קוד זה מתמקד בנושא שעליו מדבר הפרק - משתנים. הוא אינו מכיל את כל הנדרש לתוכנית שלמה. אם ננסה לבנות קטע קוד זה, המהדר יתלונן.
כיצד נבדיל בין השניים, וכיצד נהפוך קטעי קוד לתוכניות שלמות?
- קוד המספיק לתוכנית שלמות חייב להכיל את ההפונקציה main, כלומר, חייב להראות כך
int main()
{
<code_snippets>
return 0;
}- אם מופיע רק קטע קוד, אז כדי להפכו לתוכנית שלמה, יש להכניס אותו בין הסוגריים המסולסלים, במקום code_snippets בסוגריים המסולסלים לעיל.